미디어 파이프
Media pipe는 Google이 만든 Machine Lunning Solution 얼굴 추적, 손 추적, 물체 인식 등 다양한 기능 제공한다.
Media pipe에서 제공하는 기능은 아래에서 확인할 수 있습니다.
자세한 내용은 공식 홈페이지를 참조하십시오.

https://google.github.io/mediapipe/
인기글
홈
Cross-platform, customizable ML solutions for live and streaming media.
google.github.io
이러한 많은 기능 중에서 내가 사용하는 것은 Pose 기능입니다.
Pose 기능은 사람의 자세를 탐색하는 기술로 기계 학습으로 학습한 모델을 이용하여 이미지, 동영상, 실시간 동영상에서 사람의 자세를 탐색한다.
반환 값은 좌표 값이며, 이것을 통해 캔버스에 사람의 해골을 찍거나 grid를 이용하여 3D 화면에서 렌더링이 가능합니다.
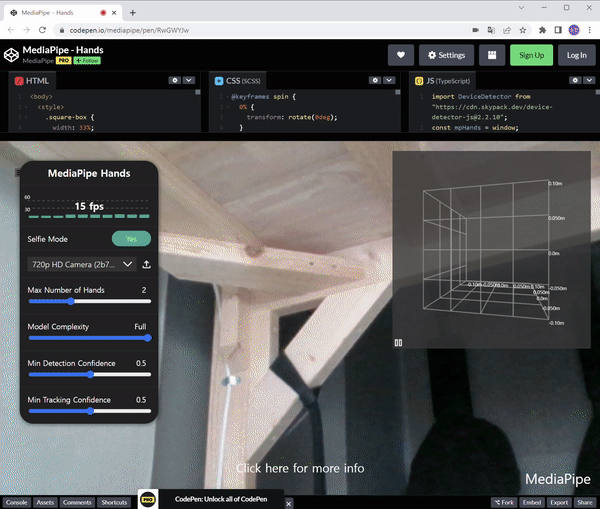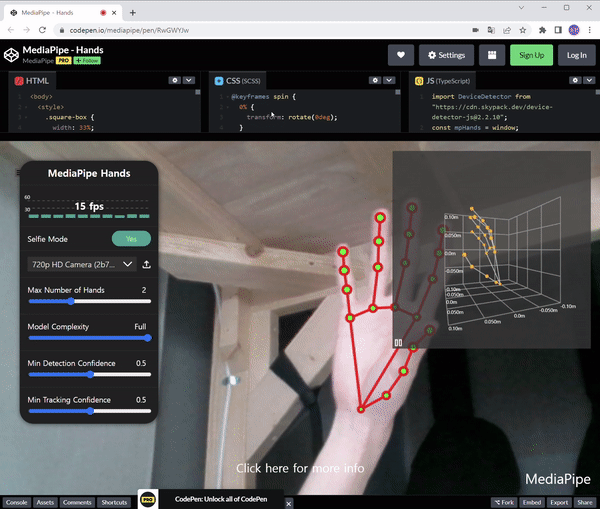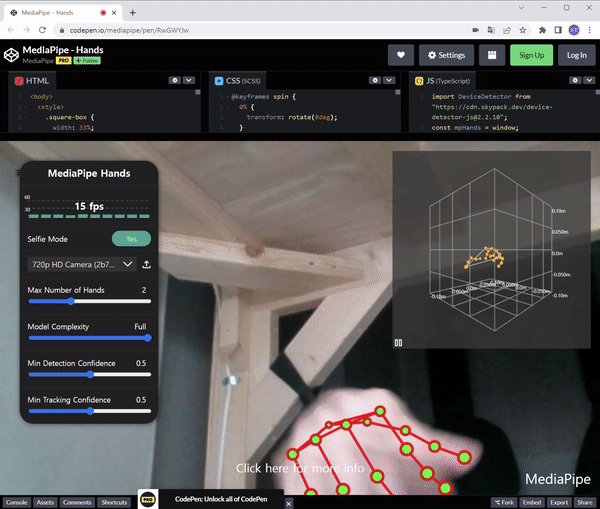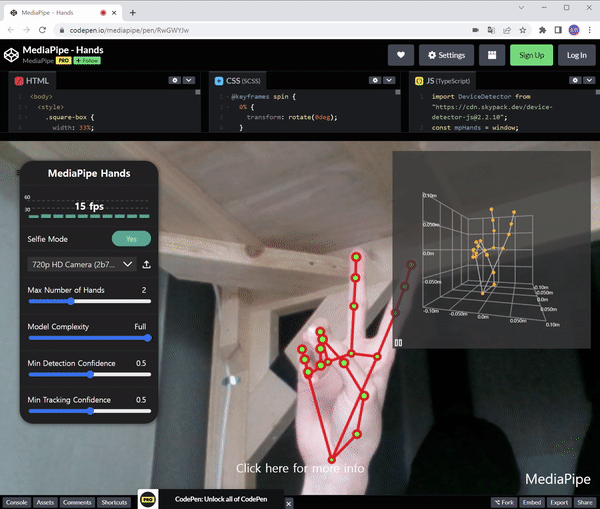
자세한 Pose Estimation에 대해 더 알고 싶다면 이전 게시물을 참조하십시오.
간단한 Pose 테스트와 Hands 추적 테스트도 가능합니다.
https://olrlobt./49
(API) 다양한 Pose Estimation API 비교 및 구성
Pose Estimation Pose estimation은 인공 지능과 컴퓨터 비전 기술을 사용하여 이미지와 비디오에서 인간의 포즈 (자세)를 감지하고 추정하는 기술입니다.
이미지 예: 동영상 예: 예를 들어, 이전에 업로드
olrlobt.
Media pipe JavaScript 구현
저는 현재 Spring 장난감 프로젝트에서 Pose estimation을 테마로하고 있으며 JavaScript로 구현했습니다.
가져오기
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/pose/pose.js" crossorigin="anonymous"></script>
Media pipe의 Pose Detection 모델 호출
const pose = new Pose({
locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/pose/${file}`;
}
});Pose 모델을 호출하여 변수 pose로 선언합니다.
쉽게, “https://cdn.jsdelivr.net/npm/@mediapipe/pose/패키지에서 Pose 객체를 가져오고 locateFile 함수를 통해 경로에서 필요한 파일을 가져옵니다.
Pose Detection 설정
pose.setOptions({
upperBodyOnly: true,
modelComplexity: 1,
smoothLandmarks: true,
enableSegmentation: false,
minDetectionConfidence: 0.5,
minTrackingConfidence: 0.5
});
upperBodyOnly: (기본값 false)
– 상체만 탐색할지 여부를 설정합니다.
– true로 설정하면 화면에 상체만 나왔을 때는 상체만 탐색하지만, 전신이 나오면 전신을 탐색한다.
– false로 설정하면, 화면에 상체만이 나와도 전신을 모두 탐색하려고 하고, 전신이 나오면 전신을 모두 탐색한다.
– 결론적으로 전신을 전부 탐색할 필요가 없어 퍼포먼스적 게인을 보려면 true로 해보자.
modelComplexity: (기본값 1)
– 모델의 복잡성 (0,1,2) 값을가집니다.
– 값이 높을수록 정밀도가 높아지고 속도가 느려집니다.
smoothLandmarks: (기본값 true)
– 추적 결과를 부드럽게합니다.
– false 설정 이 결과는 더 정확하지만 부드럽지는 않습니다.
enableSegmentation: (기본값 false)
– 비디오 세분화를 사용할지 여부.
– 이 기능을 사용하여 동영상에서 전경과 배경을 분리할 수 있습니다.
minDetectionConfidence: (기본값 0.5)
– 물체를 검출하는 최소 점수입니다.
(0-1)의 값을 갖는다.
– 값이 높을수록 정확도가 높아지지만 더 많은 노이즈가 발생합니다.
minTrackingConfidence: (기본값 0.5)
– 추적할 객체의 신뢰도(0-1) 값을 가집니다.
– 값이 높을수록 정확도가 높아지지만 더 많은 추적 실패가 발생합니다.
이 외에도 많은 옵션이 있지만, 기본적으로는 이 정도만 알면 된다.
Pose Detection 콜백 함수 설정
pose.onResults((results) => {
console.log(results);
});onResults 메서드를 통해 콜백 함수를 설정합니다.
onResults의 경우 Pose Detection이 발생할 때마다 실행됩니다.
간단한 코드의 경우는 위와 같이 작성해, 좀 더 복잡도가 오르는 경우나 재호출하는 경우는 따로 함수를 선언해, 이하와 같이 선언해 보자.
pose.onResults(onPose);
function onPose(results) {
console.log(results);
}
Pose Detection 실행
pose.send({
image: user_video
});기본 형식은 위와 같습니다.
send() 메서드의 image 속성으로 분석할 대상(이미지, 비디오, 실시간 영상)을 입력합니다.
입력에 대한 자세한 내용은 다음을 참조하십시오.
1. 이미지
pose.send({ image: user_image });user_image 변수에 html의 img 태그를 연결하여 분석을 시작한다.
2. 비디오
function processVideo() {
pose.send({ image: user_video });
requestAnimationFrame(processVideo);
}user_video 변수에 html의 video 태그를 연결해 준다.
send 의 image 속성명으로부터 알 수 있듯이, image 는 video 내의 1 프레임을 의미합니다.
따라서 processVideo 함수를 재귀 호출하여 비디오를 프레임별로 send합니다.
여기서 requestAnimationFrame 함수는 애니메이션에서 Frame을 60 FPS로 조정하는 역할을 합니다.
requestAnimationFrame 없이 재귀 호출을 하면 초당 60개 이상의 Frame을 보내고 호출 과부하가 발생할 수 있습니다.
requestAnimationFrame(processVideo,{
maxFPS: 30,
skipFrames: 2
})
}프레임 수를 줄이려면 위와 같이 호출할 수 있습니다.
여기서 maxFPS는 최대 FPS를,
skipFrames는 넘기는 프레임 수를 조정합니다.
예를 들어, maxFPS 30, skipFrames 2의 경우, 최대 FPS는 30을 초과하지 않고, Frame을 2개당 1개를 분석하게 된다.
3. 실시간 영상
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/camera_utils/camera_utils.js" crossorigin="anonymous"></script>camera = new Camera(user_video, {
onFrame: async () => {
await pose.send({ image: user_video });
},
width: 1280,
height: 720
});
camera.start();실시간 이미지의 경우 비디오 분석과 유사합니다.
먼저 mediapipe의 카메라 객체를 만듭니다.
user_video의 경우 html의 video 요소이며 onFrame은 camera 객체가 프레임을 가져올 때마다 실행됩니다.
즉, 비디오 분석에서 requestAnimationFrame()의 역할을 한다.
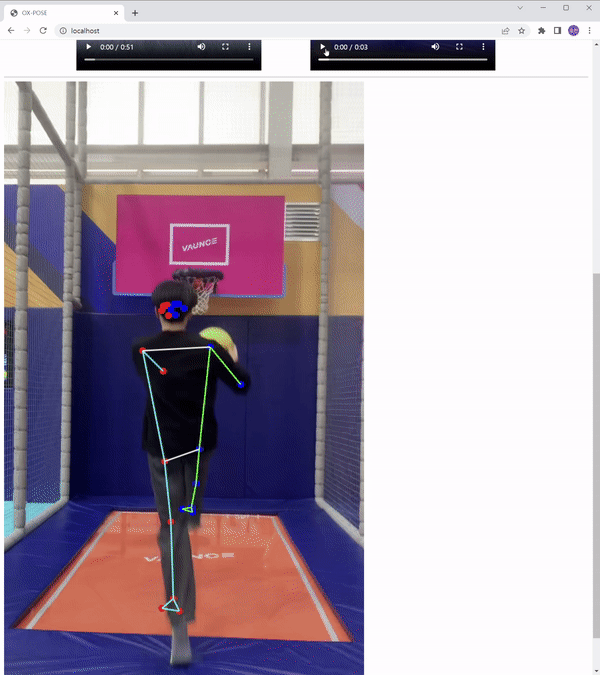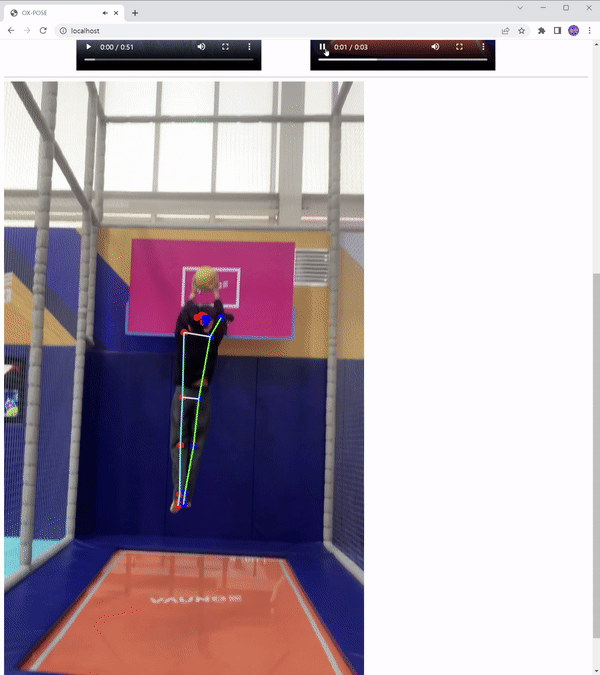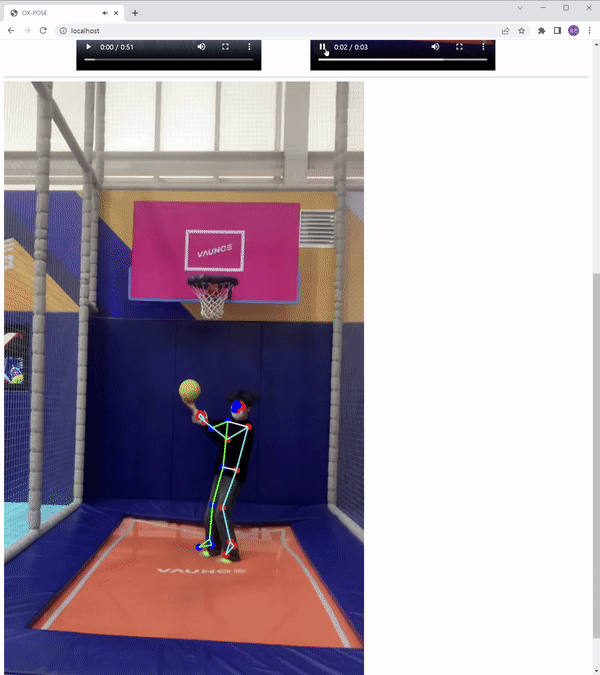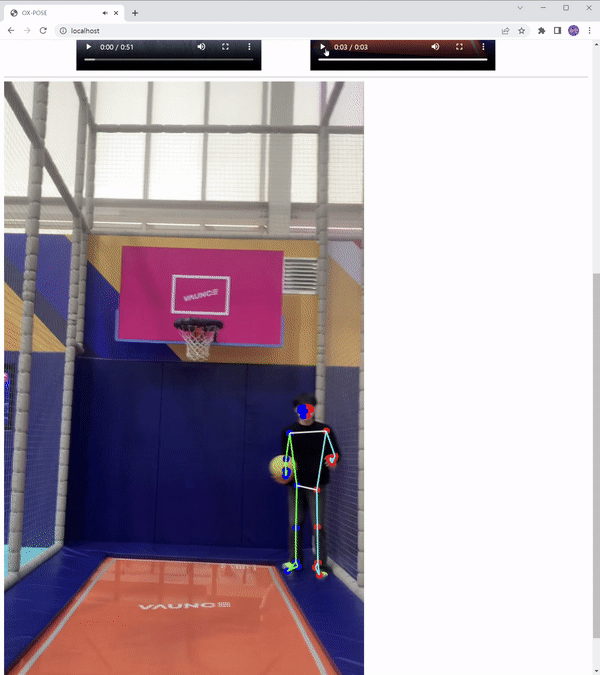
결과

총 33개의 키포인트
poseLandmarks에서는 이미지 기준에서 x, y, z, 좌표 및 visibility 점수를,
poseWorldLandmarks는 인물 기준에서 x, y, z 좌표 및 visibility 점수를 제공합니다.
visibility 점수는 0과 1 사이의 값이며 신뢰성을 의미하며 1에 가까울수록 신뢰성이 높아집니다.
Canvas로 Skeleton 그리기
콜백 함수 만들기
pose.onResults(onPose);onResult의 콜백 함수에 씁니다.
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/drawing_utils/drawing_utils.js" crossorigin="anonymous"></script>const canvasElement = document.getElementsByClassName('output_canvas')(0);
const canvasCtx = canvasElement.getContext('2d');
function onPose(results) {
// console.log(results);
canvasCtx.save(); // 캔버스 설정 저장
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height); // 캔버스 초기화
// 캔버스에 이미지 넣기
canvasCtx.drawImage(results.image, 0, 0, canvasElement.width, canvasElement.height);
drawLandmarks(canvasCtx, results.poseLandmarks, { // 랜드마크 표시
color: '#FF0000', lineWidth: 2
});
drawConnectors(canvasCtx, results.poseLandmarks, POSE_CONNECTIONS,{ // 연결 선 표시
color: '#0000FF', lineWidth: 3
});
canvasCtx.restore(); // 캔버스 설정 불러오기
}
clearRect()로 캔버스를 초기화한 후,
drawLandmarks() 와 drawConnectors() 로 골격을 그립니다.
여기서 save() 와 restore() 가 마지막과 처음에 있는 이유는 캔버스의 초기 설정값을 저장하기 때문이다.
아무것도 작성되지 않은 상태에서 save() 를 해주지 않으면 캔버스를 원래의 설정으로 되돌릴 수 없다고 한다.
결과

Canvas Skeleton 좌우로 구분
각 메소드를 잘 이해하고 있으면, 간단하게 좌우를 구별해 표현할 수 있다.
// 좌측 키 값 // 우측 키 값
const leftIndices = (1, 2, 3, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31);
const rightIndices = (4, 5, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32);
const leftConnections = ( // 좌측 연결선
(11,13),(13,15),(15,21),(15,17),(15,19),(17,19),
(11,23),(23,25),(25,27),(27,29),(27,31),(29,31)
);
const rightConnections = ( // 우측 연결선
(12,14),(14,16),(16,22),(16,18),(16,20),(18,20),
(12,24),(24,26),(26,28),(28,30),(28,32),(30,32)
);
const centerConnections = ( // 중앙 연결선
(11,12),(23,24)
);
function onPose(results) {
//console.log(results);
const keyPoint = results.poseLandmarks;
let leftKeyPoint = (); // 좌측 키포인트
let rightKeyPoint = (); // 우측 키포인트
if (keyPoint !
= null) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
canvasCtx.drawImage(results.image, 0, 0, canvasElement.width, canvasElement.height);
for (let i = 0; i < keyPoint.length; i++) { // 키포인트 구분
if (leftIndices.includes(i)) {
leftKeyPoint.push(keyPoint(i));
} else {
rightKeyPoint.push(keyPoint(i));
}
}
drawLandmarks(canvasCtx, leftKeyPoint, {
color: '#FF0000', lineWidth: 2
});
drawLandmarks(canvasCtx, rightKeyPoint, {
color: '#0000FF', lineWidth: 2
});
drawConnectors(canvasCtx, keyPoint, leftConnections,{
color: '#00FFFF', lineWidth: 3
});
drawConnectors(canvasCtx, keyPoint, rightConnections,{
color: '#00FF00', lineWidth: 3
});
drawConnectors(canvasCtx, keyPoint, centerConnections,{
color: '#EEEEEE', lineWidth: 3
});
canvasCtx.restore();
}
}
결과