데이터베이스를 모델링하는 과정에서 성능을 향상시키기 위해 다양한 프로세스를 거치게 되지만 정규화, 반정규화 등의 경과 성능과 관련된 사항을 데이터 모델링에 반영해야 합니다.
.
정규화(Nomalization)란?
정규화는 관계형 데이터베이스의 데이터 중복을 최소화하기 위해 데이터를 구조화하는 프로세스로, 각 단계에서 비정상적인 현상을 제거하고, 무결성을 유지하며, 스토리지 공간까지 효율적으로 사용할 수 있습니다.
① DB 변경 시 이상 현상(삽입 이상, 갱신 이상, 삭제 이상)을 제거
②DB구조 확장시에 재설계를 최소화하여 어플리케이션 프로그램에 미치는 영향을 최소화
③ 각 관계에 중복된 속성을 삭제하고 여러 관계로 분할
인기글
④ DB에 어떤 관계도 표현 가능
⑤ 효과적인 검색 알고리즘 생성
제1정규화(1NF)
테이블 열이 원자 값(속성)을 갖도록 테이블을 분해하는 프로세스입니다.
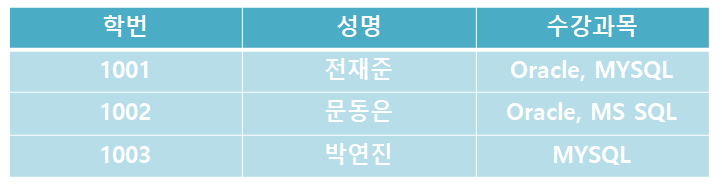
위 표를 보면 정재준과 문동은 두 개 이상의 과목을 수강했기 때문에 첫 번째 정규형을 충족하지 못한다.
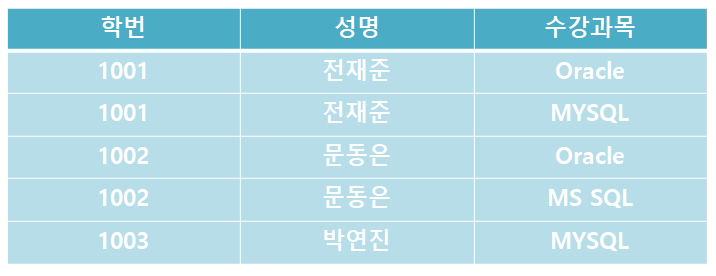
따라서 각 열이 원자 값을 가질 수 있도록 데이터를 분해하고 다음과 같이 테이블을 작성해야 합니다.
제2정규화(2NF)
첫 번째 정규형을 채우고 테이블을 전체 함수 종속성으로 만드는 것입니다.
완전 함수 종속성은 기본 키의 하위 집합이 결정자가 되지 않는다는 것입니다.
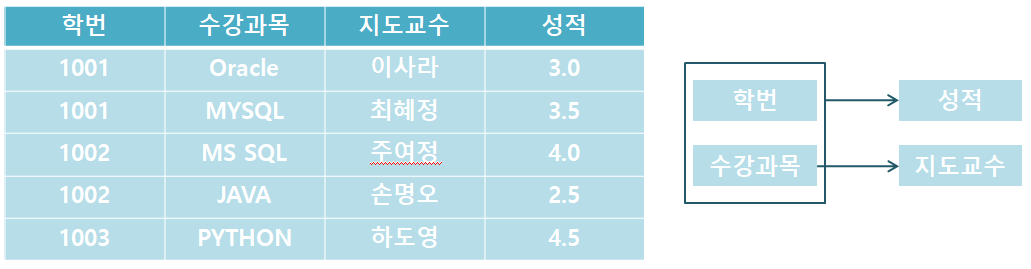
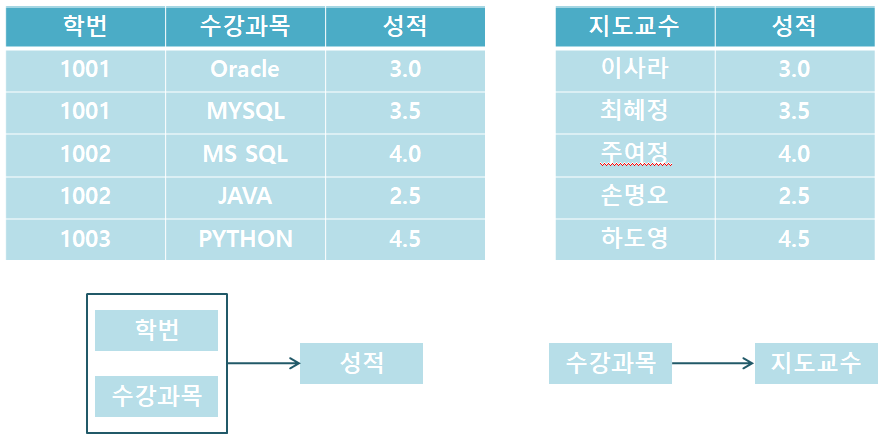
위 표에서 (학번 + 수강 과목) 기본 키로 성적을 알 수 있습니다.
그러나 기본 키 내의 (수강 과목)이라는 부분 집합으로 지도 교수를 결정할 수 있기 때문에 완전 함수 의존을 만족시키지 않습니다.
따라서 위의 표에서 지도 교수의 표를 분리하여 두 개의 표로 만들어야 합니다.
제3정규화(3NF)
두 번째 정규형을 충족하고 이행 함수의 종속성을 제거하는 것입니다.
이행 함수 의존이란, A→B, B→C의 경우, A→C가 성립하는 것입니다.
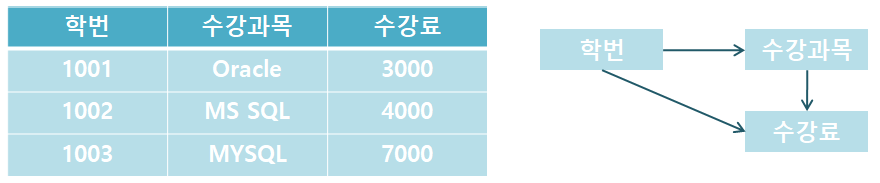
위의 표에서 학번에서 수강 과목을 알 수 있으며, 수강 과목에서 수강료를 알 수 있습니다.
이를 통해 학부에서 수강료를 알 수 있습니다.
따라서 테이블에 이행 함수 종속성이 있으므로 수강 과목 테이블을 분리하여 이행 함수 종속성을 제거해야 합니다.
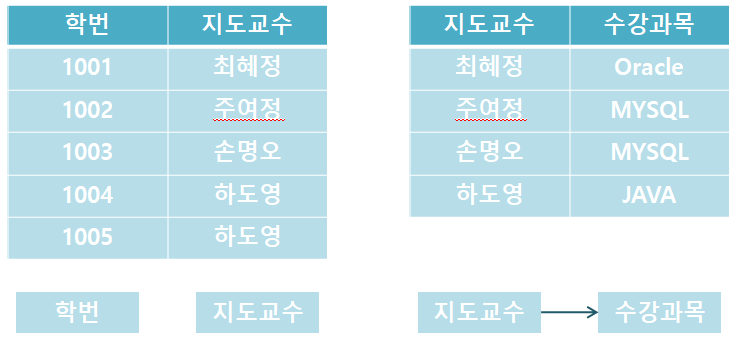
BCNF 정규화
세 번째 정규형을 만족하고 모든 결정자가 후보 키가되도록 설계하는 것입니다.

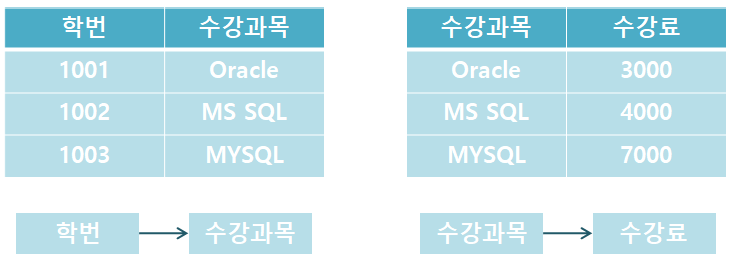
위 표에서 (학번 + 수강 과목) 기본 키로 지도 교수를 알 수 있습니다.
그러나, 하나의 수강 과목을 복수의 지도 교수가 가르칠 수 있기 때문에, 수강 과목→지도 교수의 의존은 성립하지 않습니다.
한편, 지도 교수 → 수강 과목은 성립하지만, 지도 교수가 후보가 아니라는 문제가 있습니다.
따라서 위의 테이블에서 지도 교수 테이블을 분리하여 이행 함수의 종속성을 제거해야 합니다.