ㅁ개요
O 프로그램 소개
– 이번 기사는 이전 기사 (Python GUI 음성 파일 텍스트 추출기 – 2. 파일 변환)에 이어 세 번째 글로우 wav 파일로 변환 후 Google의 speech_recognition 모듈을 이용하여 음성을 텍스트로 변환하는 방법 에 대해 보자.
O 완성된 프로그램 실행 화면
– 최종 완성된 프로그램의 결과 화면은 다음과 같습니다.
1. 프로그램을 실행하면 다음과 같이 실행됩니다.

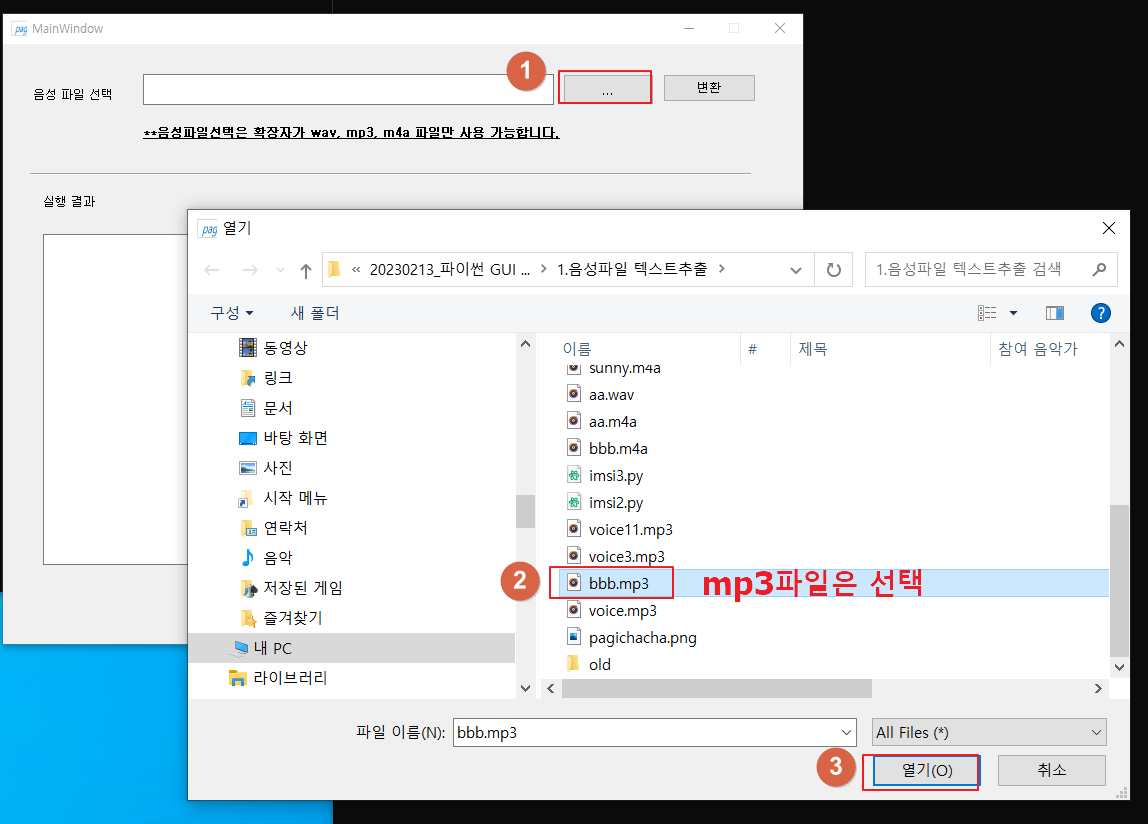
2. 오디오 파일(wav, mp3, m4a에서 선택 1)을 선택하고 열기 버튼을 클릭합니다.
인기글
 Python의 기본 명령 배우기")
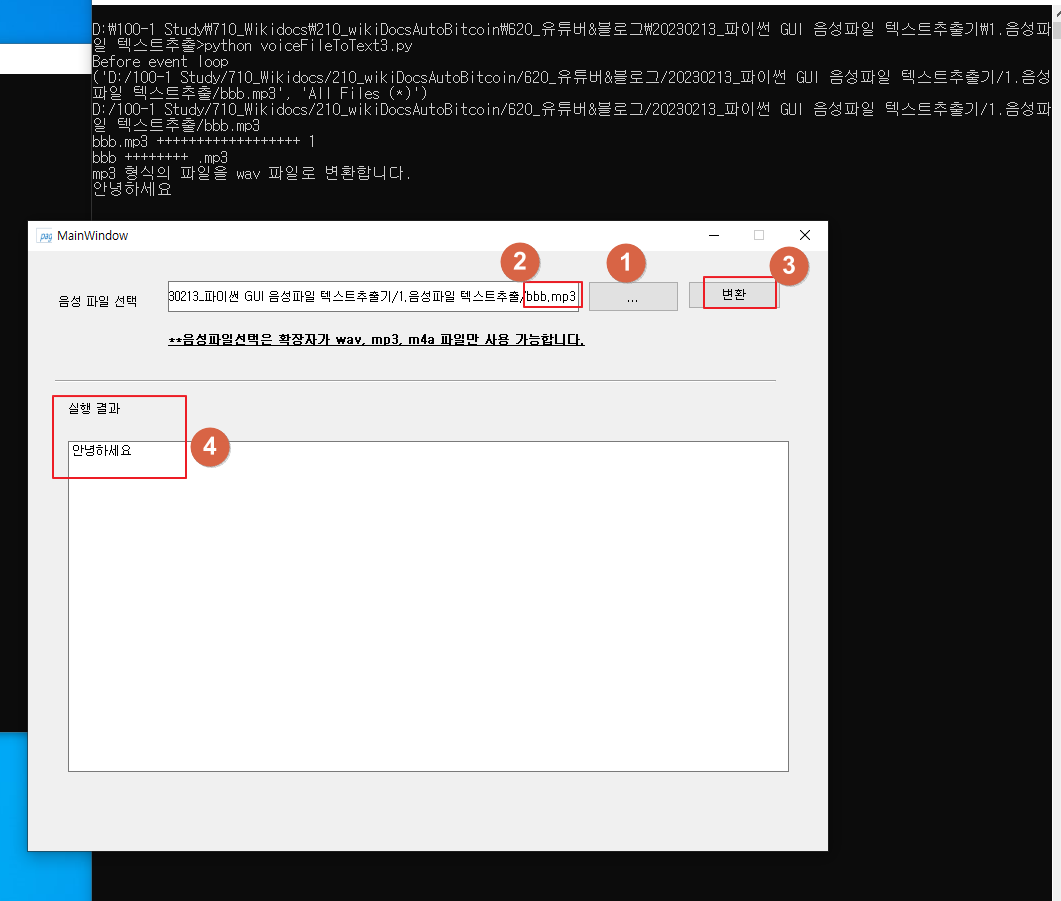
3. 다음과 같이 변환 버튼을 클릭하면 오디오 파일이 텍스트로 변환되어 실행 결과 아래에 출력됩니다.
(여기에서는 오디오 파일 bbb.mp3 파일의 내용은 “안녕하세요”만 포함되어 있습니다.
)
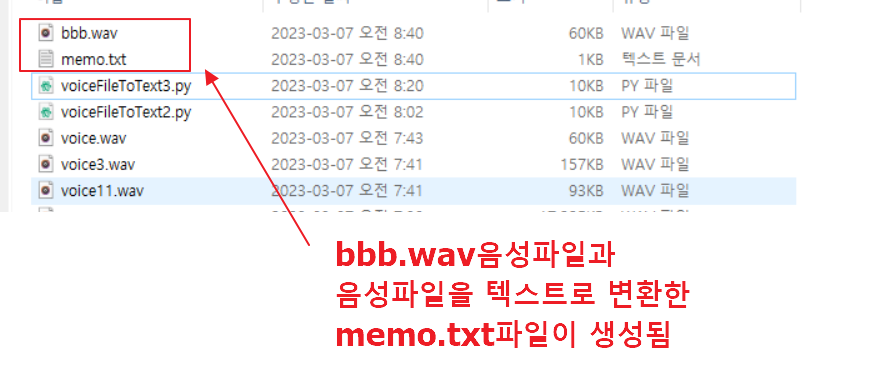
4. 실제 실행 폴더로 가서 확인 결과 아래와 같이 ‘bbb.mp3 -> bbb.wav’파일로 잘 변환되어 ‘memo.txt’파일이 새로 생성되었습니다.
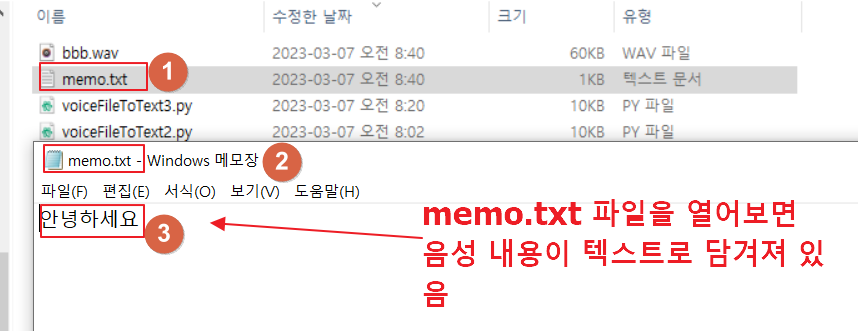
5. ‘memo.txt’ 파일을 열면 오디오 내용이 텍스트로 저장되어 있는지 확인할 수 있습니다.
ㅁ 상세
O 완성된 소스
출처: voicefileToText.py
# -*- coding: utf-8 -*-
import sys
from PyQt5.QtWidgets import *
from PyQt5 import uic, QtWidgets
import os
from PyQt5.QtGui import *
import speech_recognition as sr # 음성인식 모듈
import pydub
import webbrowser as wb
# from pydub import AudioSegment
import time
form_class = uic.loadUiType("voiceTotext.ui")(0)
class MyWindow(QMainWindow, form_class):
def __init__(self):
super().__init__()
self.setFixedSize(800,600)
self.setWindowIcon(QIcon("pagichacha.png"))
self.setupUi(self)
self.pushButton.clicked.connect(self.voiceToText)
self.toolButton.clicked.connect(self.selectFile)
def m4aToWav(self, fromVoiceFile): # 휴대폰 통화 녹음파일
# m4a_file="sunny.m4a"
# wav_filename="sunny.wav"
voiceFile = fromVoiceFile
name, ext = os.path.splitext(voiceFile)
dir = os.path.dirname(file(0))
os.chdir(dir)
m4asound = pydub.AudioSegment.from_file(fromVoiceFile, format="m4a")
m4asound.export(name+".wav", format="wav")
def mp3ToWav(self, fromVoiceFile): # 일반 음악 파일
voiceFile = fromVoiceFile
name, ext = os.path.splitext(voiceFile)
dir = os.path.dirname(file(0))
os.chdir(dir)
mp3sound = pydub.AudioSegment.from_mp3(fromVoiceFile)
mp3sound.export(name+".wav", format="wav") # mp3 -> wav파일로 변환
def voiceToText(self):
if self.lineEdit.text():
voiceFile = os.path.basename(file(0))
print(voiceFile, "++++++++++++++++++ 1")
name, ext = os.path.splitext(voiceFile)
print(name, "++++++++", ext)
dir = os.path.dirname(file(0))
os.chdir(dir)
if not (ext == '.m4a' or ext == '.mp3' or ext == '.wav'):
print("m4a, mp3, wav 파일이 아닙니다.
")
print("m4a, mp3, wav 파일 외에는 음성파일을 사용할 수 없습니다.
")
self.textEdit.setText("m4a, mp3, wav 파일 외에는 음성파일을 사용할 수 없습니다.
")
else:
if ext == '.m4a':
print("m4a 형식의 파일을 wav 파일로 변환합니다.
")
self.textEdit.setText("m4a 형식의 파일을 wav 파일로 변환합니다.
")
self.m4aToWav(voiceFile)
elif ext == '.mp3':
print("mp3 형식의 파일을 wav 파일로 변환합니다.
")
self.textEdit.setText("mp3 형식의 파일을 wav 파일로 변환합니다.
")
self.mp3ToWav(voiceFile)
elif ext == '.wav':
print("wav 형식의 파일을 선택하셨습니다.
")
self.textEdit.setText("wav 형식의 파일을 선택하셨습니다.
")
else:
print("m4a, mp3, wav 파일 외에는 음성파일을 사용할 수 없습니다.
")
self.textEdit.setText("m4a, mp3, wav 파일 외에는 음성파일을 사용할 수 없습니다.
")
time.sleep(3)
# 음성인식 부분
r = sr.Recognizer()
harvard = sr.AudioFile(name+'.wav')
with harvard as source: #<---------------- 여기 에러부터 다시 시작
audio = r.record(source) # .wav파일을 오디오 데이터 인스터스로 만듦
text = r.recognize_google(audio, language="ko-KR") # 만들어진 오디오 데이터 인스턴스를 다시 구글 음성인식 모듈로 텍스트로 변환함
print(text) # 구글 번연(AI)으로 음성(.wav)파일의 음성을 텍스트로 변환
self.textEdit.setText(text)
with open('memo.txt', 'w') as f: # memo.txt 파일로 번역된 텍스트 저장
f.write(str(text)+"\n")
else:
print("음성파일을 선택하지 않았거나, 파일명을 입력하지 않았습니다.
")
self.textEdit.setText("음성파일을 선택하지 않았거나, 파일명을 입력하지 않았습니다.
")
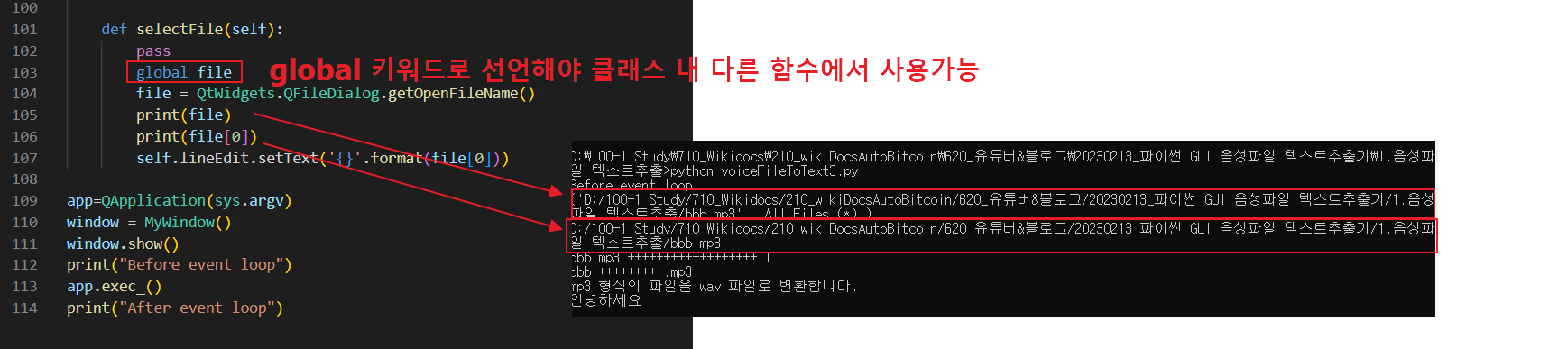
def selectFile(self):
pass
global file
file = QtWidgets.QFileDialog.getOpenFileName()
print(file)
print(file(0))
self.lineEdit.setText('{}'.format(file(0)))
app=QApplication(sys.argv)
window = MyWindow()
window.show()
print("Before event loop")
app.exec_()
print("After event loop")
O 주요 내용
관련 소스를 살펴보겠습니다.
1. GUI 창을 표시하기 위해 관련 모듈을 가져오고 미리 작성한 UI를 로드하기 위해 form_class 변수에 지정한 후 초기화 함수를 작성합니다.
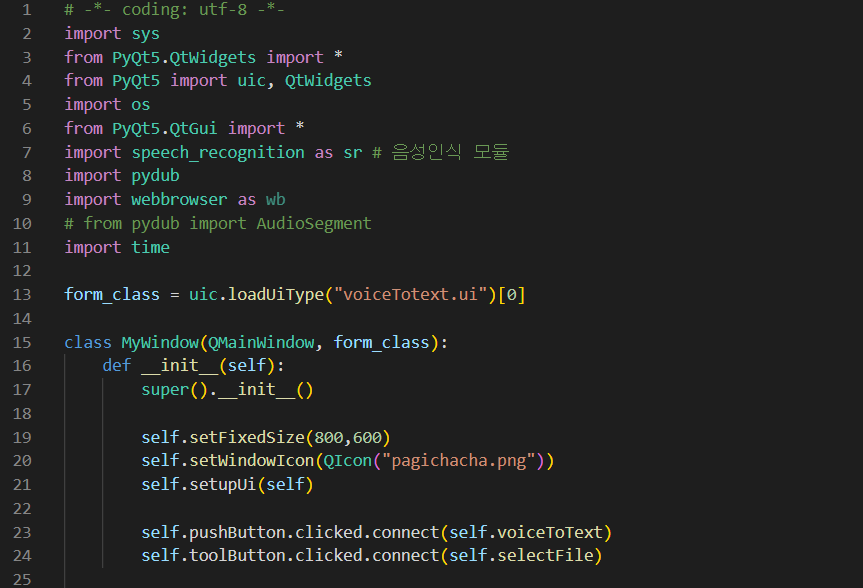
※GUI 윈도우의 떠오름에 대한 자세한 설명은 아래 링크를 참조하십시오.
https://pagichacha./10
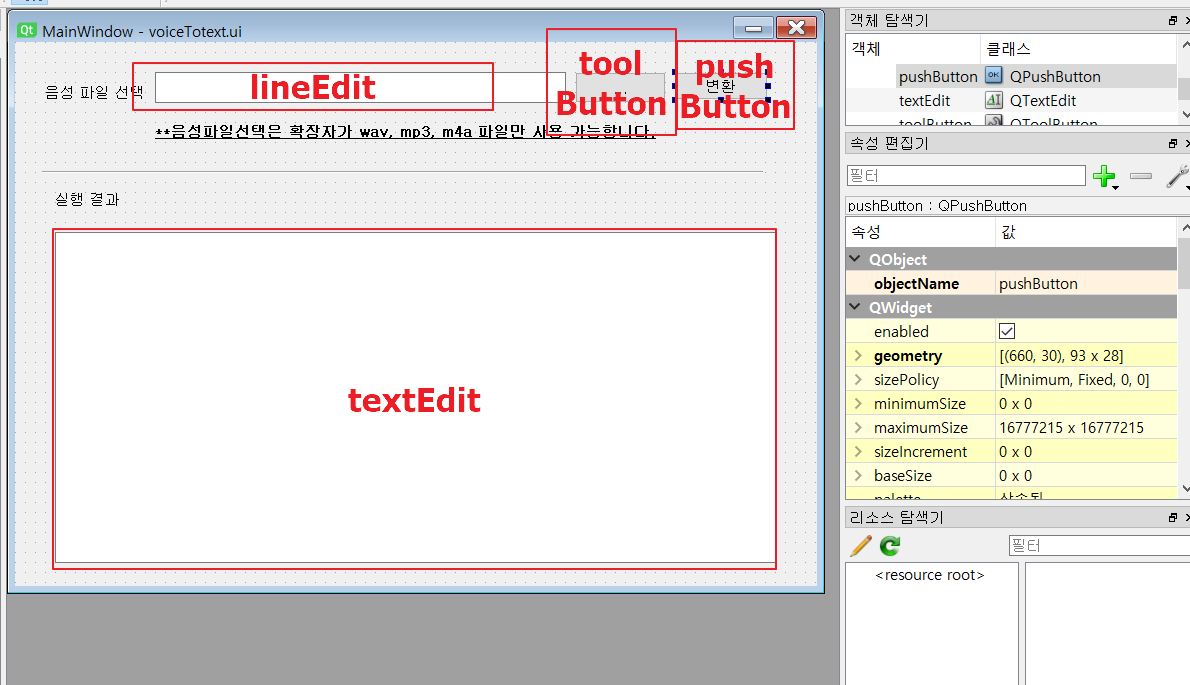
덧붙여서, qt designer에서의 오브젝트의 이름은, 다음과 같이 크게 4개로 구성되어 있습니다.
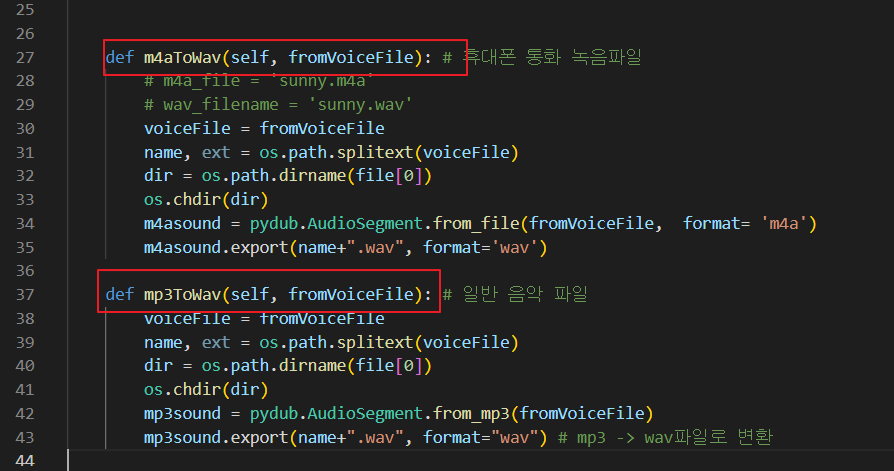
2. 이전 기사에서 설명한 변환 프로그램을 읽을 수 있도록 아래 코드와 같이 함수형으로 둡니다.
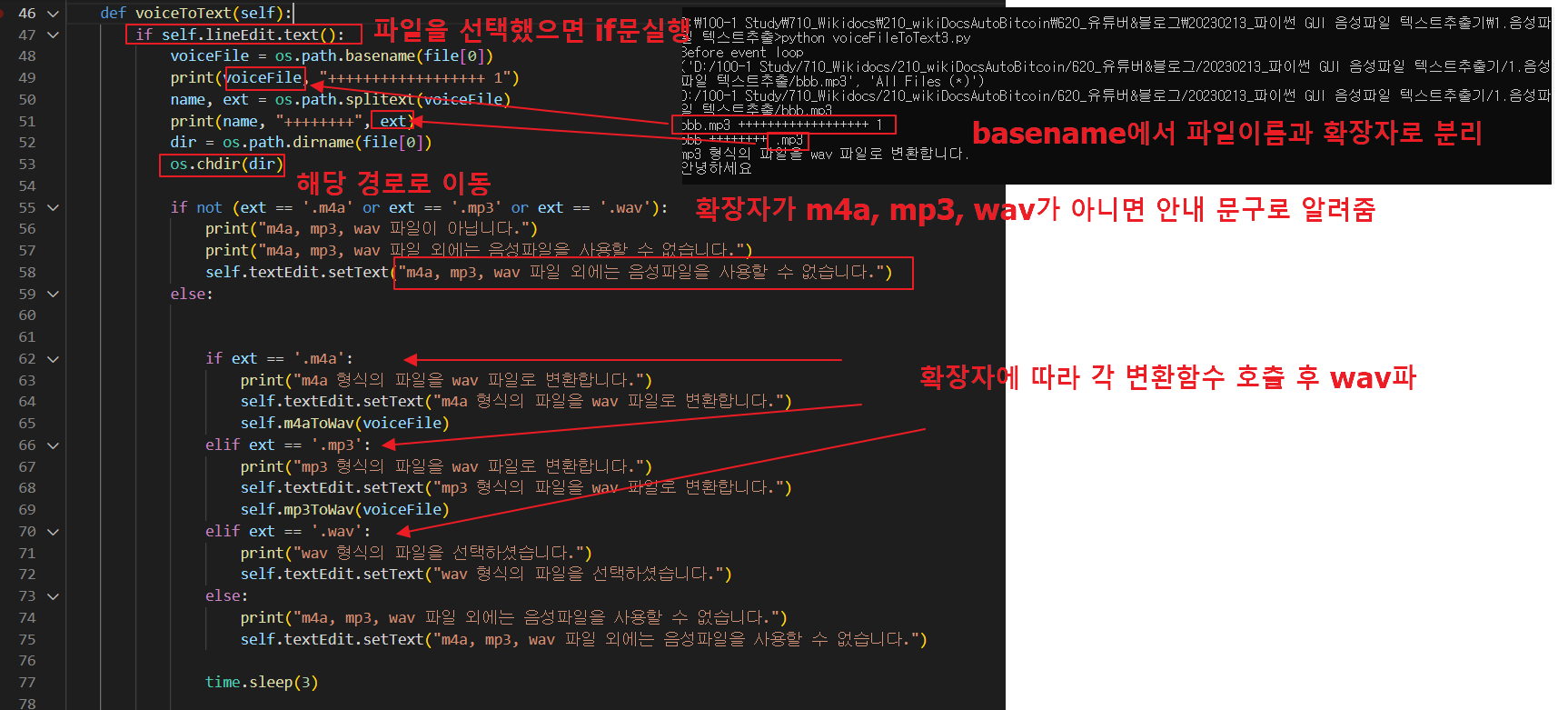
3. 실제 wav 파일로 변환하는 부분의 소스 코드입니다.
먼저 파일을 선택했는지 확인한 후 선택한 후 if 문을 실행합니다.
(라인 47)
확장자가 mp3, m4a, wav 파일 정도만 텍스트 추출을 가능하게 할 예정이므로, 파일명 부분과 확장자를 나눌 필요가 있으므로, 이를 위해서는 다음과 같이 코딩합니다.
voiceFile = os.path.basename(file(0)) <-- 'bbb.mp3' 와 같이 파일 이름 + 확장자만 빼기
여기서는 파일 이름과 확장자를 다시 분리하기 위해 splitext() 함수를 사용합니다 (line 50).
그리고 우리가 프로그램을 실행한 위치에 wav 파일을 생성해야 하기 때문에 다음 위치로 이동합니다.
dir = os.path.dirname(file(0)) <-- 'D:/100-1 Study/710_Wikidocs/210_wikiDocsAutoBitcoin/620_YouTube&Blog/20230213_Python GUI 음성 파일 텍스트 추출/1. 음성 파일 텍스트 추출‘
os.chdir (dir) <-- 위의 경로로 이동 (line 53)
4. 다음 코드는 위에서 변환된 wav 파일을 읽고 텍스트로 변환하는 부분입니다.
어려운 내용은 없으므로 아래 코드의 코멘트를 참고하십시오.

5. 변환할 오디오 파일을 선택하는 부분입니다.
여기서 주의해야 할 점은 file 변수를 global로 선언해야 하지만 클래스의 다른 함수에서 사용할 수 있습니다.
ㅁ정리
O 우리가 배운 내용
harvard = sr.AudioFile(name+’.wav’)
with harvard as source:
이것으로 “Python GUI 음성 파일 텍스트 추출기”의 게시물을 종료합니다.
여기까지 읽어 주셔서 감사합니다.
코멘트그리고 마음나는 이글을 지속시키는 힘됩니다.
감사합니다.
※추가 정보는 아래와 같은 YouTube 영상에서 해당 내용을 보다 자세하게 보실 수 있습니다.