캐시 메모리
대부분의 프로그램은
한번 사용한 데이터를 재사용할 가능성이 높다(시간적 지역성)
그 주변의 데이터도 곧바로 사용할 가능성이 높다(공간적 지역성)
데이터의 지역성을 가지고 있다.
데이터의 현지화를 활용하여 메인 메모리에 있는 데이터를 캐시 메모리에 호출하고 CPU가 필요한 데이터를 캐시에서 먼저 찾도록 하면 시스템 성능을 향상시킬 수 있다.
| 시간적 지역성(Spatial 지역) | 공간적 지역성(Temporal 지역) |
|
|
| 반복 루프 서브루틴 공통 변수 LRU |
배열(Array) 프리페치 |
ex)
for (i=0; i<10; i++)
data(i+1) = data(i) + 1;
data(1) = data(0) + 1;
data(2) = data(1) + 1;| (시간적 지역성) data(1) 은 다음 순환에서 읽습니다. |
(공간적 지역성) data(0) 부터 data(9) 까지 read |
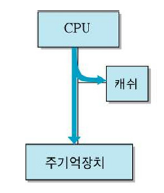
어느 프로그램을 동작시키기 위해서는 메모리에 적재되어 CPU가 할당되어야 동작이 된다.
이 때, CPU와 메모리(RAM) 사이에서 활발하게 데이터를 교환하게 되지만, CPU에 비해 비교적 속도가 느린 메모리에 의해 올바르게 성능을 발휘할 수 없다.
캐시 메모리는 CPU와 RAM 사이에서 발생하는 병목 현상을 줄입니다.
사용하고 싶다.

CPU에는 이러한 캐시 메모리가 2~3개 정도 사용된다.
(L1, L2, L3 캐시 메모리라고 함)
속도와 크기에 따라 분류한 것으로, 일반적으로 L1 캐시로부터 먼저 사용된다.
(CPU에서 가장 빨리 액세스하고 여기에서 데이터를 찾을 수 없으면 L2로 설정)
캐시 메모리에 데이터가 있으면 메인 메모리에 액세스할 필요가 없습니다.
(읽을 때)
캐시 메모리로 데이터를 교환하는 알고리즘은 다음과 같다.
캐시 메모리에서는 페이지 대신 프레임 또는 메모리 블록
- 페이지 : 가상 메모리를 일정 크기로 나눈 집합으로 보조 기억 장치에서 사용
- 프레임 : 메인 메모리 블록 (아래 기술)
FIFO(First In First Out)

OPT(Optimal)

LRU(Least Recently Used)

그 밖에도
LFU – Least Frequently 사용 : 참조 횟수가 최소인 페이지 바꾸기
MFU – Most Frequently used: 참조 횟수가 가장 많은 페이지 바꾸기
NUR – Not Used Recently: 최근에 사용되지 않은 페이지 교체
등 다양하게 있다.
이때,
CPU가 참조하려고 하는 메모리가 캐시에 존재하고 있는 경우, Cache Hit라고 한다.
CPU가 참조하고 싶은 메모리가 캐시에 존재하지 않는 경우 (Page Fault) Cache Miss이라고 한다.
Cache Hit Rate = Cache Hit 수/기억 액세스의 총 수
캐시 히트가 발생하면 캐시에서 데이터를 읽는 것만으로 충분합니다.
그러나 데이터를 변경하는 경우 캐시 메모리에서만 종료하는 대신 주 메모리에 있는 데이터도 변경해야 합니다.
캐시 히트시 쓰기 정책
| 구분 | Write Through | Write Back |
| 구성도 |
|

|
| 개념 | 쓰기 동작시 캐시와 메인 메모리의 동시에 데이터 변경 | 먼저 캐시에만 쓰고 데이터 스왑 아웃(페이지 교환) 시 주 메모리에 복사 |
| 장점 | 구조 단순, 캐시 – 저장 장치 일관성 | 횟수 최소화, 시간 단축 |
| 단점 | 버스 트래픽 증가, 쓰기 시간 증가 | 캐시 – 저장 장치 일관성 문제(Cache Coherency) |
| 이 경우, 캐시 메모리의 이점이 저하된다. |
Write Back 레코딩 정책을 사용하면 레코딩된 내용을 다시 변경할 때 디스크에 두 번 레코딩할 필요가 없으며 변경된 내용을 하나씩 레코딩하는 대신 모아서 한 번에 레코딩할 수 있다는 이점이 있습니다. . (모으기보다 빠르다. ) 대신 캐시에 일시적으로 저장된 내용을 아직 디스크에 쓰지 않았지만 컴퓨터를 끄면 문제가 생긴다. 컴퓨터를 끄기 전에 올바르게 종료해야 하는 이유 중 하나가 이 때문입니다. |
캐시 미스가 발생하면 메인 메모리에서 데이터를 검색하여 캐시 메모리에 할당하거나 할당하지 않습니다.
캐시 미스시 쓰기 정책
| 구분 | no-Allocate | Allocate |
| 구성도 |

|

|
| 개념 | 쓰기 동작시 메인 메모리에만 쓰기, 캐시에 할당하지 않음 | 메인 메모리 블록을 캐시 메모리에 할당하고 캐시 메모리에 쓰기 |
| 그런데 Write-back + Write-allocate 방식이 일반적으로 사용된다. |
||
cache는 보통 block size가 32Byte 또는 64Byte이다.
(32비트 64비트 운영 체제에 따라 다르다는 이야기도 있다.
)
그렇다면 Memory는 1Byte 단위로 액세스하지만 Cache는 왜 이렇게 큰 단위로 액세스합니까?
1Memory에서 data를 가져오는데 비용이 들기 때문에 한 번에 많이 가져오는 것이다.
예를 들어 캐시 미스가 발생하는 경우 블록에서 하나의 데이터만 바꾸는 대신 블록 단위로 전체를 바꿔야 합니다.
주소를 1개 주어 1개의 word를 임포트하는 것을 4회 반복하는 것보다 한 번에 4개를 임포트하는 것이 게인이기 때문이다.

이 때문에 공간지역성(Spatial locality), 캐시에 이미 저장된 동일한 블록의 데이터에 액세스하면 캐시 효율이 크게 향상됩니다.
클래스/구조체 패딩 바이트
이 예에서는 캐시 메모리 블록보다 메모리
32비트 운영 체제 – 4바이트
64비트 운영 체제 – 8바이트
한 번에 액세스하는 이유의 예입니다.
#include <stdio.h>
struct temp {
int a; // 4byte
int b; // 4byte
char c; // 1byte
char d; // 1byte
double e; // 8byte
short f; // 2byte
};temp 구조체가 사용하는 데이터는 20바이트인 것으로 보이지만 실제로는 32바이트입니다.

(위의 경우는 8바이트)

32비트 CPU를 예로 하면 위와 같이 읽혀지지만 패딩 바이트를 사용하지 않으면 위와 같이 마지막 1byte가 남아 연산을 2회 처리하게 된다.

패딩 바이트를 추가해 1회의 연산에 1개의 값이 들어가게 되어, 메모리는 한층 더 사용합니다만, CPU는 1회의 동작만 하면 좋기 때문에 연산이 보다 빨리 처리된다.
이렇게 공간 낭비인 패딩 공간을 확보하면서 메모리의 크기를 맞추는 이유는 캐시 히트율을 높이고 CPU 연산을 줄이기 때문이다.