1. Redis란?
- Key, Value 구조의 비정형 데이터를 관리 및 저장하기 위한 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템입니다.
(DBMS) - 데이터베이스, 캐시, 메시지 브로커로 사용되며 메모리 내 데이터 구조가 있는 스토리지입니다.
- key, value 리포지토리에서 가장 순위가 높습니다.
1) 메모리 내 데이터 구조 리포지토리를 사용하는 이유
- 유저가 많지 않은 경우는, WEB-WAS-DB의 구조에서도 DB에 무리가 없지만, 유저가 많아지면 무리가 간다.
- 캐시는 한 번에 읽은 데이터를 임의의 공간에 저장하고 다음에 읽을 때 즉시 결과 값을 검색하는 데 도움이 됩니다.
- 동일한 요청이 여러 번 들어오면 캐시 서버에서 즉시 결과 값을 제공하여 속도를 높이고 DB 부하를 줄입니다.
2) 캐시 서버의 두 가지 패턴
- Look aside cache
- 클라이언트가 데이터를 요청
- 서버는 먼저 데이터가 존재하는지 캐시 서버에 확인합니다.
- Cache 서버에 데이터가 있는 경우 DB에 데이터를 쿼리하지 않고 Cache 서버의 결과 값을 클라이언트에 직접 반환(Cache Hit)
- Cache 서버에 데이터가 없으면 DB에 데이터를 쿼리하여 Cache 서버에 저장하고 결과 값을 클라이언트에 반환합니다.
- Write back
- 웹 서버는 모든 데이터를 Cache 서버에 저장합니다.
- Cache 서버에 일정 시간 데이터가 저장됨
- Cache 서버의 데이터를 DB에 저장
- DB에 저장된 Cache 서버의 데이터 삭제
- 웹 서버는 모든 데이터를 Cache 서버에 저장합니다.
3)Redis 특징
- Key, Value 구조이므로 쿼리를 사용할 필요가 없습니다.
- 데이터를 디스크에 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 빠릅니다.
- String, Lists, Sets, Sorted Sets, Hashes 데이터 구조를 지원합니다.
- 문자열 : 가장 일반적인 key-value 구조의 유형입니다.
- 세트 :String 세트입니다.
여러 값을 하나의 값으로 둘 수 있습니다.
게시물 태그와 같은 장소에서 사용할 수 있습니다. - Sorted Sets : 중복 데이터가 없는 Set 구조에 정렬 Sort를 적용한 구조로, 랭킹 보드 서버 등의 구현에 사용할 수 있습니다.
- 리스트 : Array 형식의 데이터 구조입니다.
목록을 사용하면 처음과 끝에 데이터를 삽입하고 빼는 것이 빠르지만 중간에 데이터를 삽입하거나 삭제하는 것은 어렵습니다.
- 문자열 : 가장 일반적인 key-value 구조의 유형입니다.
- Single Threaded 입니다.
: 한 번에 하나의 명령만 처리할 수 있습니다.
따라서, 도중에 처리 시간이 긴 명령이 들어가면, 그 후의 명령은 모두 이전의 명령이 처리될 때까지 대기가 필요합니다.
(그러나 get, set 명령의 경우, 초당 10만 개 이상 처리할 수 있을 정도로 빠릅니다.
)
4) Redis 사용시주의 사항
- 서버에 장애가 발생하면 이를 위한 운영 계획이 필요합니다.
: 인메모리 데이터스토어의 성격상, 서버에 장해가 발생했을 경우, 데이터 손실이 발생할 가능성이 있기 때문입니다. - 메모리 관리가 중요합니다.
- 단일 스레드의 특성상 한 번에 하나의 명령만 처리할 수 있습니다.
처리에 시간이 걸리는 요청, 명령은 피해야 합니다.
2. ElasticSearch
- 일반적인 검색 엔진은 웹에서 정보를 수집하고 검색 결과를 제공합니다.
DB의 비정형 데이터를 인덱싱하고 검색하는 것은 불가능합니다. - 탄력적 검색은 비정형 데이터를 색인화하고 검색할 수 있습니다.
- 또한 장점 중 하나인 역색인 구조를 사용하여 신속한 검색이 가능합니다.
- 역 색인 : 키워드로 문서를 찾는 방법
1) 관계형 데이터베이스와의 비교
인기글
| 탄력적 검색 | 관계형 데이터베이스 |
| 색인 | 데이터베이스 |
| 샤드 | 파티션 |
| 유형 | 테이블 |
| 문서 | 행 |
| 필드 | 열 |
| 매핑 | 스키마 |
| Query DSL | SQL |
- 용어
- 스키마 : 데이터베이스의 구조와 제약에 대한 전반적인 사양을 설명하는 것
- Attribute(속성), Entity(객체), Relation(관계), 제약
- 스키마 : 데이터베이스의 구조와 제약에 대한 전반적인 사양을 설명하는 것
2) 특징
- 기본적으로 HTTP를 통해 JSON 형식의 RESTFul API를 사용 가능
- Scale Out : 샤드에 의해 규모가 수평으로 늘어날 수 있다.
- 고가용성: Replica로 데이터 신뢰성 확보
- 스키마 무료 : Json 문서를 통해 데이터 검색을 수행하기 때문에 스키마 개념이 없습니다.
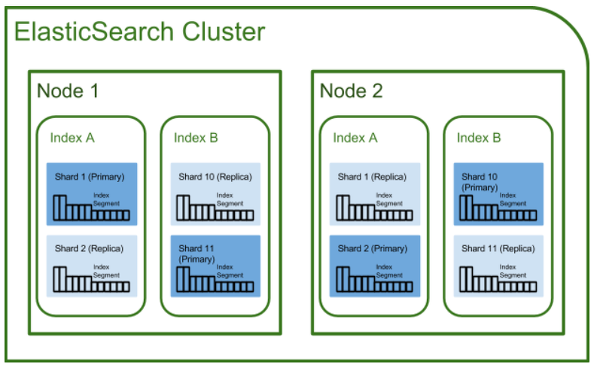
- 클러스터: 탄력적 검색에서 가장 큰 단위 시스템, 적어도 하나 이상의 노드로 구성된 노드 모음. 서로 다른 클러스터는 데이터 액세스 및 교환이 불가능한 독립 시스템으로 유지되며, 여러 서버가 하나의 클러스터를 구성할 수 있으며, 하나의 서버에 여러 클러스터가 있을 수 있습니다.
- 노드: 탄력적 검색을 구성하는 단일 단위 프로세스를 의미합니다.
- master-eligible node : 클러스터를 제어하는 마스터로 선택할 수 있는 노두
- 색인 생성, 삭제
- 클러스터 노드 추적, 관리
- 데이터 입력 시 어떤 샤드에 할당할 것인가
- 데이터 노드: 데이터와 관련된 CRUD 작업과 관련된 노드, CPU 및 메모리와 같은 리소스를 많이 소비하고 모니터링이 필요하며 마스터 노드와 분리하는 것이 좋습니다.
- Ingest node: 데이터 변환과 같은 전처리 파이프라인을 실행하는 역할
- Coordination only node : data node 및 master-eligible node 작업을 대체하는 이 노드는 대규모 클러스터에 큰 이점이 있습니다.
즉, 로드 밸런서와 비슷한 역할을 한다고 봅니다.
- master-eligible node : 클러스터를 제어하는 마스터로 선택할 수 있는 노두
- 인덱스/샤드/복제
- Index: RDMBS에서 데이터베이스에 해당하는 개념
- sharding : 데이터를 분산하고 저장하는 방법, elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 분할했습니다.
기본적으로 하나가 존재하고 검색 성능 향상을 위해 클러스터의 샤드 수를 조정하는 튜닝도 한다. - replica : 다른 형태의 샤드라고 할 수 있다.
노드가 손실되면 데이터의 신뢰성을 위해 샤드를 복제합니다.
따라서 Replica는 다른 노드에 존재하는 것이 좋습니다.

3) 탄성 검색의 이점
- 오픈 소스 검색 엔진: Apache Foundation의 Lucene을 기반으로 개발된 오픈 소스 검색 엔진
- 전문 검색(Full Text): 전체 콘텐츠를 색인화하여 특정 단어가 포함된 문서를 검색합니다.
- 통계 분석: 비정형 로그 데이터를 수집하고 한 곳에서 수집하여 통계를 분석할 수 있습니다.
ex) 키바나 - 멀티테넌시: 검색할 필드명으로 복수의 인덱스를 한번에 조회할 수 있다.
- 역색인: 역색인 구조를 사용하여 특정 단어를 찾을 때 문서 전체에서 검색하는 대신 단어를 포함하는 특정 문서의 위치를 찾아 신속하게 결과를 찾을 수 있습니다.
- 분산 환경: 데이터를 샤드라는 작은 단위로 나누어 제공한다.
데이터를 분산하고 신속하게 처리합니다.
4) 탄력적 검색의 단점
- 실시간이 아닙니다.
인덱싱된 데이터는 1초 후에도 검색이 가능하며 실시간으로 검색할 수 없습니다.
내부적으로 커밋, 플래시 등의 복잡한 프로세스를 거친다. - 트랜잭션 및 롤백 기능 없음: 전체 클러스터의 성능을 향상시키기 위해 비용이 많이 드는 롤백 및 트랜잭션 기능이 없습니다.
- 데이터 업데이트를 제공하지 않음: 탄력적 검색은 문서를 수정하지 않습니다.
엘라스틱 검색으로 업데이트하는 기존 문서를 삭제하고 다시 삽입하는 방식이다.
3. CI/CD: 연속 통합(Continuous Integration)/연속 배포(Continuous Deployment)
- 매번 개발자가 코드를 수정하고, 빌드하고 테스트하고, 배포하는 데 시간이 걸립니다.
- 그러나 git에 코드를 올리는 것만으로도 누군가가 빌드와 테스트, 배포까지 해주면 시간 단축이 된다.
1) CI란?
- 빌드/테스트 자동화 프로세스
- 애플리케이션에 대한 새로운 코드 변경이 정기적으로 빌드 및 테스트되고 공유 리포지토리에 통합되므로 여러 개발자가 동시에 애플리케이션 개발과 관련된 코드를 조작할 때 충돌하는 문제를 해결할 수 있습니다.
- CI 실행은 정기적으로 소스/버전 관리 시스템에 대한 변경 사항을 커밋하고 모든 사람에게 동일한 작업 기반을 제공하는 것으로 시작됩니다.
- 커밋시 빌드와 테스트가 자동으로 이루어져 동박을 확인하여 변경으로 인해 문제가 발생하는 부분이 없음을 보증
- CI/CD 파이프라인 구현을 위한 첫 번째 단계입니다.
2) CD란?
- 배포 자동화 프로세스
- 지속적인 서비스 제공(Continuous Delivery) 및 지속적인 배포(Continuous Deployment)
- 빌드, 테스트, 배포 단계를 자동화하는 DevOps 방식을 극한까지 끌어올립니다.
코드 변경이 파이프라인의 이전 단계를 모두 통과하면 수동 개입 없이 변경 사항이 프로덕션 환경에 자동으로 배포됩니다. - 성숙하고 입증된 지속적인 통합과 지속적인 배포 단계를 기반으로 합니다.
간단한 코드 변경이 정기적으로 마스터에 커밋되고 자동화된 빌드 및 테스트 프로세스를 거쳐 다양한 프리프로덕션 환경으로 승격되며, 문제가 발견되지 않으면 최종 배포
3) CI/CD 종
- Jenkins
- CircleCi
- TravisCi
- Github Actions
- etc
4. Docker
- Go 언어로 작성된 Linux 컨테이너 기반 오픈 소스 가상화 플랫폼
1) 가상화를 사용하는 이유
- 서버의 사용률이 낮은 서버의 자원은 낭비될 수밖에 없지만, 1개의 서버내에 모든 서비스를 올리면 안정성에 문제가 생긴다.
그래서 안정성을 높이고 리소스도 최대한 활용할 수 있는 방법으로 나타난 것이 서버 가상화다. - 대표적인 가상화 플랫폼으로는 VM이 있으며, VM은 OS 가상화입니다.
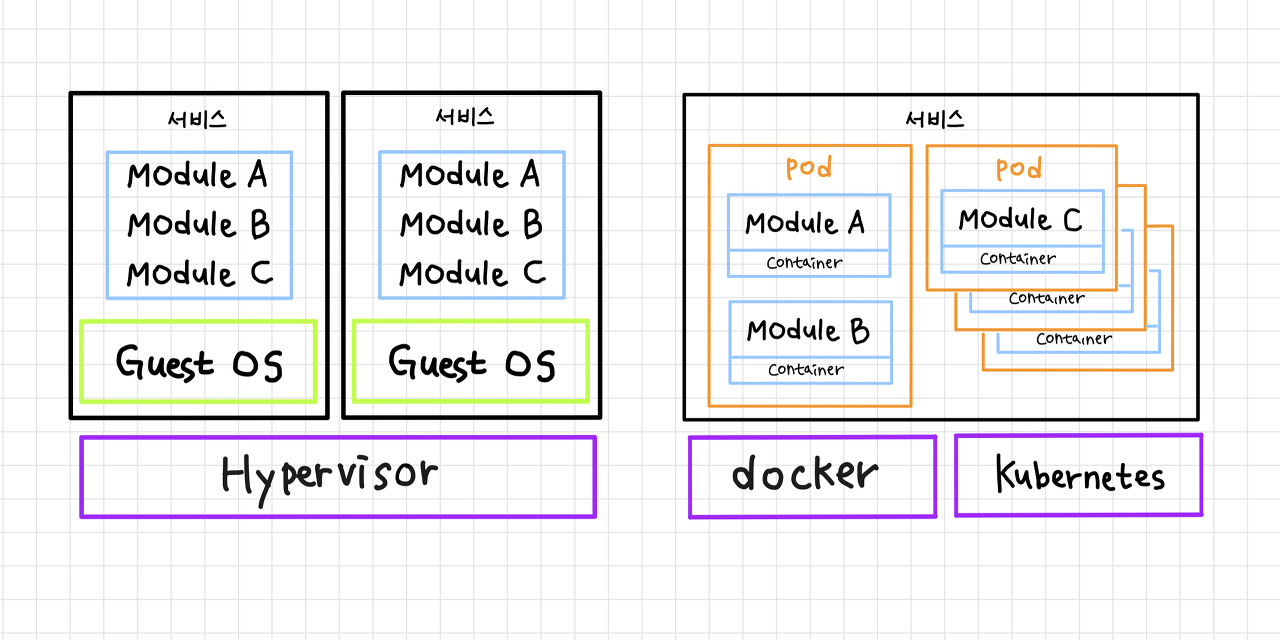
- VM: 1대의 서버가 있어 HostOS(Mac, Linux, ms윈도우 등)가 오른다.
호스트 OS에 의해 VM을 가상화시키는 하이퍼바이저(virtual box, Xen, KVM, VMware)가 있다.
하이퍼바이저를 사용하여 원하는 운영 체제에서 GuestOS를 올려 여러 VM을 만들 수 있습니다.
GuestOS도 HostOS처럼 하나의 독립 OS를 가지고 사용할 수 있습니다.
- 컨테이너: VM과 HostOS까지의 설치는 동일합니다.
이 OS에 의해 컨테이너를 가상화시켜 주는 다양한 소프트웨어 중에서 도커를 가장 많이 사용한다.
Docker를 설치하고 컨테이너 이미지를 만들면 이미지에는 서비스와 해당 서비스가 반환하는 데 필요한 라이브러리가 있습니다.
- VM과 컨테이너의 차이: 구조적으로 컨테이너는 하나의 OS를 공유하지만, VM은 각각의 OS를 띄워야 하는 구조이므로 컨테이너는 빠릅니다.
다만, VM은 호스트가 Windows일 때에 게스트로서 Linux를 인스톨 해 사용 가능하지만, 컨테이너는 Linux OS로 Windows용의 컨테이너를 사용할 수 없다.
또한 보안상 VM은 분리되어 있으며 서로 손상되지 않지만 컨테이너는 보안 문제가 발생할 수 있습니다. - 쿠버네티스: 복수의 컨테이너를 하나의 파트라라는 개념으로 묶을 수 있다.
하나의 부품이 배포 단위입니다.
- VM: 1대의 서버가 있어 HostOS(Mac, Linux, ms윈도우 등)가 오른다.
2) 컨테이너란?
- 서버의 사용률이 낮은 서버의 자원은 낭비될 수밖에 없지만, 1개의 서버내에 모든 서비스를 올리면 안정성에 문제가 생긴다.
그래서 안정성을 높이고 리소스도 최대한 활용할 수 있는 방법으로 나타난 것이 서버 가상화다.
5. Logstash
- 데이터 집계, 변환, 저장
- 형식이나 복잡성에 관계없이 데이터를 동적으로 수집, 전환 및 전송합니다.
- grok을 사용하여 비구조 데이터로부터 구조를 도출하고, IP 주소로 위치 정보 좌표를 해독하고, 기밀 필드를 익명화 또는 제외하고, 전체적인 처리를 용이하게 한다.
- 입력: 모든 형식, 크기, 소스 데이터 수집(ex. Filebeat)
- 데이터는 많은 시스템에서 다양한 형식으로 아카이브되는 경우가 많지만, Logstash는 여러 개의 공통 소스에서 이벤트를 동시에 검색하는 다양한 입력을 지원합니다.
로그, 메트릭, 웹 애플리케이션, 데이터스토어 및 다양한 AWS 서비스를 모두 지속적으로 스트리밍하는 방식으로 쉽게 수집할 수 있습니다.
- 데이터는 많은 시스템에서 다양한 형식으로 아카이브되는 경우가 많지만, Logstash는 여러 개의 공통 소스에서 이벤트를 동시에 검색하는 다양한 입력을 지원합니다.
- 필터: 데이터 이동 중 분석 및 변환(ex. Grok)
- Logstash 필터는 데이터가 소스에서 리포지토리로 이동하는 과정에서 각 이벤트를 구문 분석하고 명명 된 필드를 식별하고 구조를 구축하고이를 공통 형식으로 변환 통합하여 분석을보다 강력하게합니다.
, 비즈니스 가치를 높입니다. - Grok은 모든 텍스트를 구문 분석하고 구조화합니다.
구조화되지 않은 로그 데이터를 구조화되고 쿼리 가능한 데이터로 구문 분석하는 가장 좋은 방법입니다.
- Logstash 필터는 데이터가 소스에서 리포지토리로 이동하는 과정에서 각 이벤트를 구문 분석하고 명명 된 필드를 식별하고 구조를 구축하고이를 공통 형식으로 변환 통합하여 분석을보다 강력하게합니다.
- 출력: Stash를 선택하여 데이터 전송(ex. Elasticsearch)
- Logstash는 Elasticsearch를 포함한 모든 위치로 데이터를 라우팅할 수 있는 다양한 출력을 지원하므로 여러 스토리지로 데이터를 다운스트림할 수 있는 유연성을 확보할 수 있습니다.
- Logstash는 Elasticsearch를 포함한 모든 위치로 데이터를 라우팅할 수 있는 다양한 출력을 지원하므로 여러 스토리지로 데이터를 다운스트림할 수 있는 유연성을 확보할 수 있습니다.
1) logstash 사용 예
- 이벤트 저장
- Apache 웹 로그를 입력으로 사용
- 로그 분석
- 분석된 데이터를 Elasticsearch 클러스터에 기록하는 고급 파이프라인 생성
- 여러 I/O 플러그인을 연결하여 다양한 소스에서 데이터를 통합
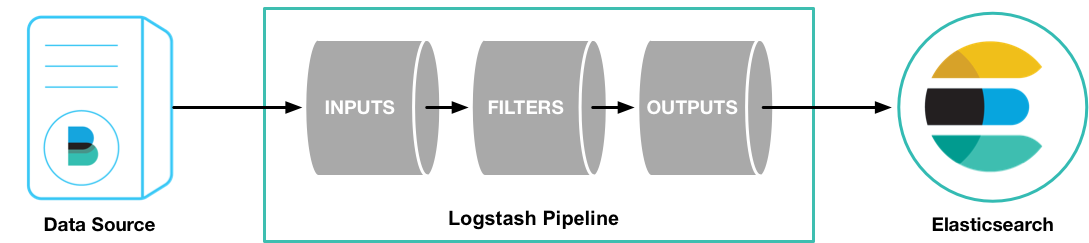
- Logstash 파이프라인에는 input(입력)과 output(출력)의 두 가지 필수 요소와 filter(필터)라는 하나의 선택적 요소가 있습니다.
입력 플러그인은 소스에서 데이터를 검색하고 필터 플러그인은 지정한 대로 데이터를 변경하며 출력 플러그인은 대상에 데이터를 씁니다.
5. 참조
1) ElasticSearch: https://victorydntmd./308
(Elasticsearch) 기본 개념 잡기
1. Elasticsearch란? Elasticsearch는 Apache Lucene (Apache Lucin) 기반 Java 오픈 소스 분산 검색 엔진입니다.
victorydntmd.
2) 탄력적 검색 기본 개념: https://devfunny./384
탄력적 검색의 기본 개념과 장점/단점
들어가고 탄력적 검색은 검색 엔진입니다.
여기서 검색 엔진 (search engine)은 웹으로부터 정보를 수집하여 검색 결과를 제공하는 프로그램이다.
우리가 자주 사용하는 데이터베이스는 비정형
devfunny.
3) 탄성 검색 및 스프링의 예: https://tecoble.techcourse.co.kr/post/2021-10-19-elasticsearch/
Spring Data Elasticsearch 설정 및 검색 기능 구현
연습 리포지토리에서 코드를 확인할 수 있습니다.
1. Elasticsearch Elasticsearch는 Apache Lucene 기반 Java 오픈 소스 분산 RESTful…
tecoble.techcourse.co.kr
4) VM과 컨테이너의 개념과 차이: https://daaa0555./464
VM(가상 머신)과 Container(컨테이너)의 차이
# VM vs Container # VM 공통으로 1개의 서버가 있어, 한편의 서버에는 어느 operating system가 있어도, HostOS(Mac OS, Linux, Microsoft Windows)가 오른다.
VM의 경우 호스트 OS에서 VM을 가상화
daaa0555.
5) Docker 핵심 개념: https://khj93./entry/Docker-Docker-%EA%B0%9C%EB%85%90
(Docker) Docker 개념과 키 설명
Docker는 Go 언어로 작성된 Linux 컨테이너 기반의 오픈 소스 가상화 플랫폼이다.
가상화를 사용하는 이유는?
khj93.
6) Logstash: https://dc2348./32
(Logstash) Logstash란 무엇입니까?
Logstash란 데이터 집계, 변환, 스토리지 서버 데이터 처리 파이프라인인 오픈 소스 Logstash는 다양한 소스에서 데이터를 수집하고 변환하여 자주 사용하는 리포지토리로 전달합니다.
Logstash는 형식입니다.
dc2348.