GPT계 LLM 모델의 zero-shot 성능을 높인 방법인 instruction-tuning에 관한 논문의 내용을 정리하고 싶다.
논문 링크).
1. Introduction
GPT3와 같은 모델은 피드 샷 성능이 (기대보다) 뛰어나다는 특징이 있지만 제로 샷 성능은 낮습니다.
FLAN은 자연어 악기와 원샷 예제를 데이터 세트로 구성하여 fine-tuning (Instruction Tuning) unseen task의 제로쇼의 성능을 높인 연구입니다.
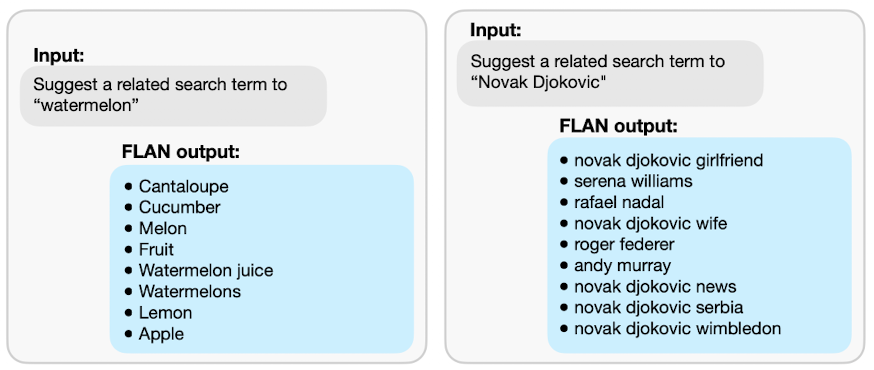
FLAN 연구의 intuition은 다음과 같습니다.
- 언어 모델(LM)에 제공되는 입력인 제로샷 프롬프트(no few-shot example)는 실제 모델이 학습한 자연 언어의 형식과 다릅니다.
- NLP task는 “Is the sentiment of this movie review positive or negative?”, “Translate ‘how are you’ into Chinese.”와 같은 자연어 형식으로 쓸 수 있습니다.
2. FLAN: Instruction Tuning Improves Zero-Shot Learning
1) Tasks & Templates
먼저 instruction+example 데이터세트를 만들기 위해 저자는 60개 이상의 NLP 데이터세트를 다시 집계하여 12개의 클러스터를 만들었습니다(multiple tasks $\rightarrow$task cluster).
인기글
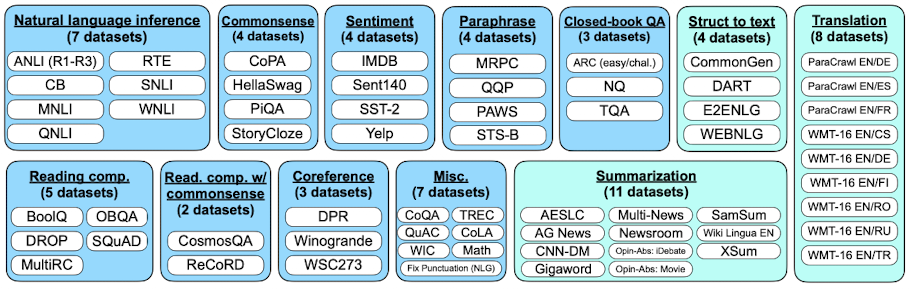
그런 다음 각 데이터 세트 (작업)마다 10 개의 템플릿을 만들고 원래 데이터 세트를 템플릿에 포함하도록 자연 언어 악기로 구성된 fine-tuning 데이터 세트를 만들었습니다.

2) Evaluation Splits
FLAN의 연구 목표는 자연 언어의 insruction을 입력했을 때의 unseen task에 대한 성능을 높이는 것이다.
따라서 저자는 12개의 태스크 클러스터를 홀드 아웃하고 train(fine-tuning)/test(validate) 세트로 나누어 실험을 진행했다.
예를 들어 SNLI 작업의 제로샷 성능을 확인하기 위해 Natural Language Inference cluster를 제외하고 학습했습니다.
3) 모델
LLM으로는 LaMDA-PT (디코더 전용 변환기 언어 모델, 137B)를 사용 하였다.
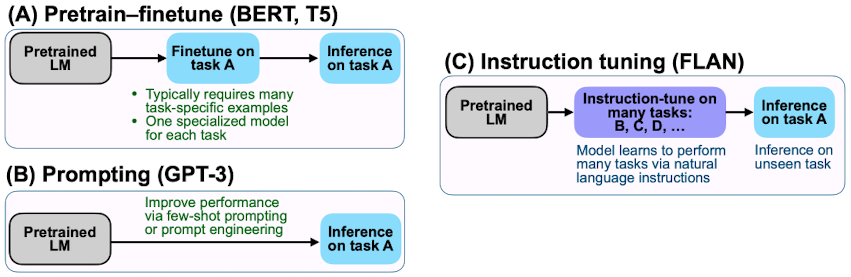
4) BERT, T5, GPT, FLAN의 차이
FLAN과 BERT, T5, GPT의 차이점은 다음과 같습니다.
i. Pretrain-finetune and prompting
- BERT, T5는 각 작업에 대해 fine-tuning
- GPT는 fine-tuning을하지 않고 prompting 만
- FLAN은 자연 언어 instruction을 가지고 fine-tuning
ii. Inference prompt 비교
- T5 프롬프트
cb hypothesis: At my age you will probably have learnt one lesson.
premise: It’s not certain how many lessons you’ll learn by your
thirties.- GPT 프롬프트
At my age you will probably have learnt one lesson.
question: It’s not certain how many lessons you’ll learn by your
thirties. true, false, or neither? answer:- Instruction Tuning (FLAN)
Premise: At my age you will probably have learnt one lesson.
Hypothesis: It’s not certain how many lessons you’ll learn by your
thirties.
Does the premise entail the hypothesis?
3. Results
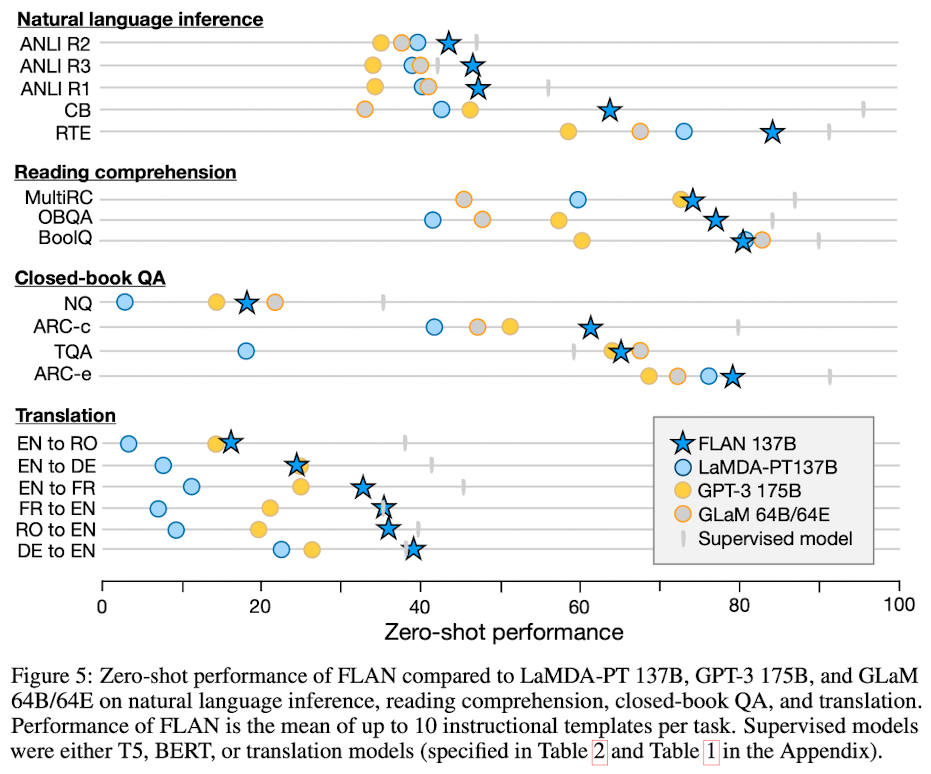
1) 제로 샷 성능
Instruction-Tuning 모델의 제로 샷 성능이 GPT3 175B보다 성능이 비슷한지 좋은지 확인할 수 있습니다.
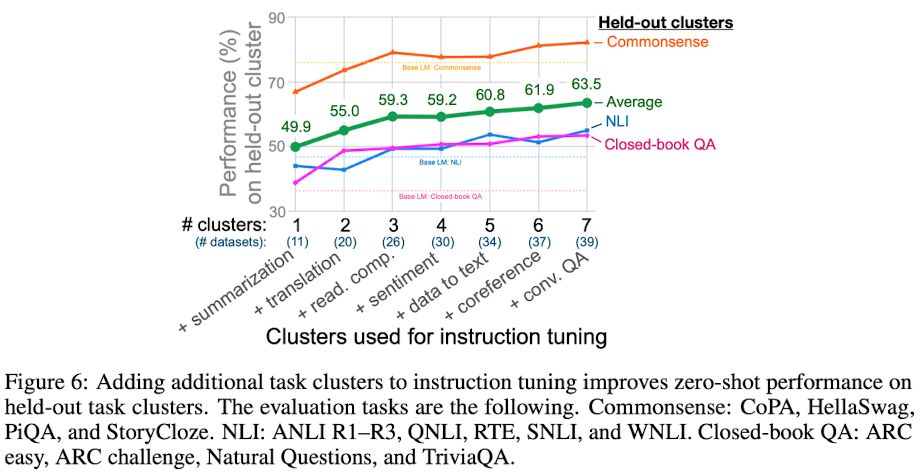
2) Number of Instruction Tuning Clusters
Instruction Tuning에 사용된 태스크 클러스터의 수가 많을수록 성능이 좋아지는 것을 확인할 수 있다.
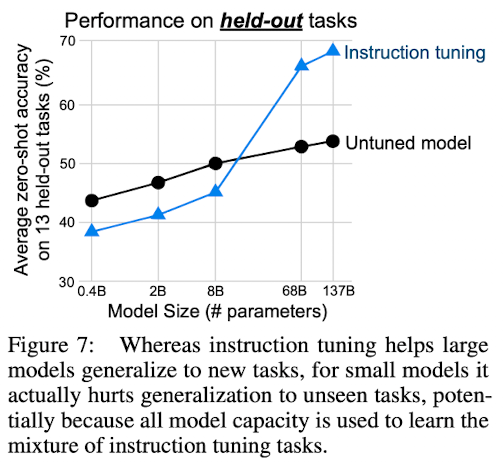
3) Scaling Law
FLAN에서도 스케일링이 증가하면 성능이 확실히 좋아지는 것을 확인할 수 있다.
4) Role of Instruction
Instruction이 존재하는 것이 없는 것보다 성능이 좋다.
- Instruction $\rightarrow$Please translate this sentence to French: ‘The dog runs.’
- no instruction $\rightarrow$ input: “the dog runs” / output: “Le chien court”
- dataset name $\rightarrow$ “(Translation: WMT’14 to French) The dog runs.”
