- Panel datas의 약어로 데이터를 조작/분석하기 위한 라이브러리
- 데이터를 통합하여 2차원 데이터로 분석할 수 있도록 가공하는 것
- 숫자만을 사용하는 헌퍼와 달리 문자, 숫자 등 다양한 데이터형을 가진 데이터를 한 번에 수정, 재배치, 연산할 수 있는 라이브러리.
- 시계열 데이터, 각종 필터링, 결측치/이상치 처리 기능
- matplotlib, seaborn 등 다양한 시각화 도구에서 사용
- 엑셀과 마찬가지로 빠르고 대용량의 데이터가 다를 수 있으며 스테로이드 맞춤 Excel이라고 불리는 강력한 도구
- 하단 C, 벡터화 연산, 구조(연속 메모리) => 고속
판다스의 특징과 장점
- 빠르고 효율적이며 다양한 표현력을 갖춘 데이터 구조
- 인덱스를 정수 이외에도 실수, 문자 등 다양한 데이터형을 설정 가능
- Excel에서 처리할 수 없는 대용량 데이터
- 다양한 종류의 데이터에 적합합니다.
이종자료형의 열을 가진 테이블데이터 시계열데이터 레이블을 가진 다양한 행렬데이터 다양한 관측 통계 데이터 인덱스를 정수 이외에 실수, 문자 등 다양한 데이터 유형으로 설정할 수 있다.
시리즈/DataFrame
시리즈
- 동일한 데이터 형식을 저장하는 인덱싱된 1차원 배열
- 사전과 마찬가지로 인덱스(index)와 값(value) 쌍
DataFrame
- Pandas의 2차원 데이터 구조
- 행과 열로 구성
- Excel 테이블 양식과 비슷합니다.
- 색인 및 열로 데이터 저장
| 구분 | Pandas | Numpy |
| 색인 자동 생성 | 사용자가 인덱싱 가능 | 숫자로 자동 생성 |
| 색인 유형 | 정수, 실수, 문자 등 다양한 데이터 유형 | 정수형 |
| 특징 | 색인을 다른 데이터 형식을 저장 데이터 변경, 삭제, 변환 가능 데이터 유형이 시리즈별로 다를 수 있습니다. |
인덱스를 정수형 데이터로 저장 자동 생성, 고속 배열 연산 데이터형이 수치형과 같은 사이즈와 형식을 가지는 |
DataFrame 만들기
인기글
DataFrame() 함수
- pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
- data : DataFrame을 구성하는 데이터 – ndarray (structured or homogeneous), Iterable, Series or DataFrame
- index : 인덱스 값을 지정할 수 있습니다
- dtype: 각 항목에 적용되는 데이터 유형
- copy: DataFrame 또는 2차원 ndarray로 DataFrame을 만들 때 얕은 복사(link)를 할지 깊은 복사를 할지 결정합니다.
True or False
arr = np.array(((1,2,3),(4,5,6)))
pd.DataFrame(arr)

# index, columns 지정해서 생성, 기본은 0부터 일련번호로
pd.DataFrame(arr, index=('a', 'b'),columns=('가','나','다'))
iterable 객체 – 반복 가능 객체 만들기
- 대표적으로 iterable 형 – list, dict, set, str, bytes, tuple, range
df1 = pd.DataFrame((4,5,6,7), index=range(0,4),columns =('A'))

#딕셔너리의 key가 칼럼명으로 들어갑니다
dic = {'a':(1,3),'b':(1,2),'c':(2,4)}
pd.DataFrame(dic)
시리즈로 작성
#시리즈로 생성
s = pd.Series(('London','NewDelhi','Washington'), index=('UK','India','US'))

데이터 파일 처리
csv 파일 로드
df = pd.read_csv(filename)
df.info()

df.head(3)
#df.tail(3)은 뒤에서 3개를 뽑음
df.shape
>>> (11, 4)
df.columns
>>> Index(('이름', '국어', '영어', '수학'), dtype="object")
df.index.tolist() # 인덱스 리스트
>>> (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
df.values
>>> array((('kate', 100.0, 90, 95.0),
('olivia', 90.0, 80, 75.0),
('emma', 95.0, 100, 100.0),
('sophia', 100.0, 100, 100.0),
('amy', nan, 35, 60.0),
('james', 70.0, 75, 65.0),
('daniel', 80.0, 90, 55.0),
('peter', 50.0, 60, nan),
('kevin', 100.0, 100, 90.0),
('jack', 90.0, 95, 70.0),
('james', 70.0, 75, 65.0)), dtype=object)대조
df.sort_values(by="국어", ascending=False) # 기본값은 True로 오름차순으로 되어있다.

데이터 추출
df.nlargest(5,'국어')df.nsmallest(5,'국어')

|

|
- df.loc(“행 인덱스명”,”열 인덱스명” )
- df.iloc(행 인덱스, 열 인덱스)(0부터 시작하는 정수형 인덱스)
- df(“열 이름”) 또는 df.열 이름
df(('국어','수학'))
#행번호로 데이터추출
df.iloc(0)
>>>
이름 kate
국어 100.0
영어 90
수학 95.0
Name: 0, dtype: object
In ( ):
#마지막행번호로 데이터추출
df.iloc(-1)
>>>
이름 james
국어 70.0
영어 75
수학 65.0
Name: 10, dtype: object
#슬라이싱으로 여러 데이터 추출
df.iloc(1:3)

#행번호로 여러 데이터 추출
df.iloc((1,3,5))
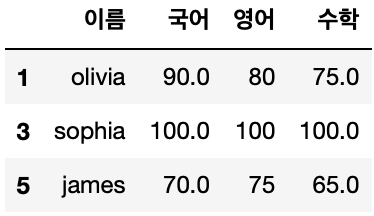
#iloc( 행번호 , 열번호 )
df.iloc(0)(0)
>>> 'kate'
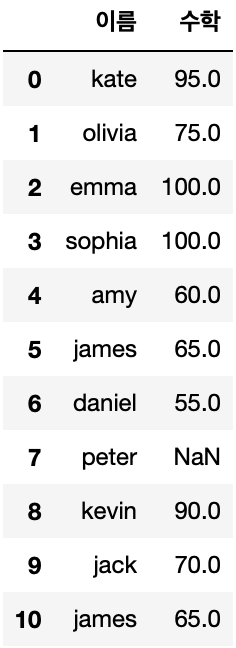
#특정열의 모든 행 추출
df.iloc(:,0)
>>>
0 kate
1 olivia
2 emma
3 sophia
4 amy
5 james
6 daniel
7 peter
8 kevin
9 jack
10 james
Name: 이름, dtype: object
#특정열들의 모든 행 추출
df.iloc(:,(0,3))
index와 loc
df.set_index('이름', inplace=True)

#인덱스로 추출
df.loc('kate')
>>>
국어 100.0
영어 90.0
수학 95.0
Name: kate, dtype: float64
#인덱스, 컬럼명으로 추출
#df.loc(인덱스, '컬럼명')
df.loc('kate','국어')
>>>
100.0#여러 인덱스, 여러 컬럼명으로 추출
#df.loc((인덱스), ('컬럼명'))
df.loc(('kate','emma'),('국어','수학'))

데이터 통계 표시
df.sum()
>>>
국어 845.0
영어 900.0
수학 775.0
dtype: float64
df.mean()
>>>
국어 84.500000
영어 81.818182
수학 77.500000
dtype: float64
df.min()
>>>
국어 50.0
영어 35.0
수학 55.0
dtype: float64
df.max()
>>>
국어 100.0
영어 100.0
수학 100.0
dtype: float64
df.describe()

# 국어점수가 가장 높은 학생
df(df.국어 == max(df('국어')))(('국어','수학'))

결측치 처리
# copy를 통해 데이터프레임 원본을 유지
df1 = df.copy()

# 결측치 확인
df1.isnull().sum()
>>>
국어 1
영어 0
수학 1
dtype: int64결측치 처리 방법에 의한 데이터 프레임 명령
#결측치 삭제
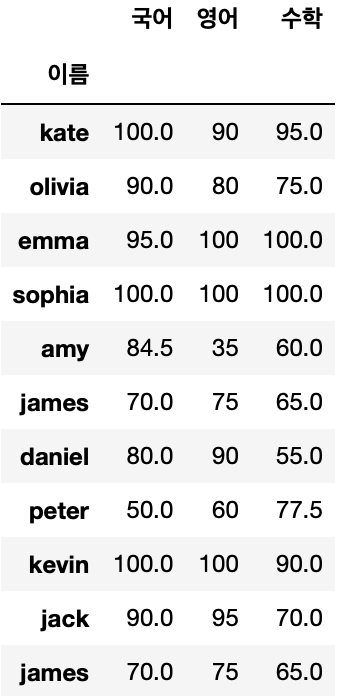
df1.dropna(inplace=True)
# inplace=True를 통해 데이터프레임내 값을 변경하겠다고 설정

# 결측치를 데이터프레임 평균값으로 대체
df1.fillna(df1.mean(), inplace=True)
추가 및 삭제
행 추가
df.loc('jia') = (100,100,100)

열 추가
df('총점')=df.sum(axis=1)
# axis = 0 은 행방향 1은 열방향

행삭제
df.drop(('jia'), inplace=True)

열 제거
df.drop(('총점','평균'),axis=1, inplace=True)
