클러스터링은 데이터 마이닝 분야에서 데이터 간의 유사성을 기반으로 데이터를 그룹으로 분류하는 기술입니다.
기계 학습의 학습은 크게 두 가지로 나뉩니다.
지도 학습(supervised learning) 그리고 비지도 학습(unsupervised learning) 이다.
클러스터링 기술은 비지도 학습에 속하지만, 비지도 학습은 별도로 데이터의 라벨이 주어지지 않는다.
대신 데이터 간의 유사도에 따라 데이터를 그룹화할 수 있습니다.
군집화라고 한다.
즉, 데이터 간의 유사성이 높은 것을 군집화하는 것을 클러스터링이라고 부른다.

위의 그림을 보면 데이터는 children, Adults 라벨 값이 존재하고 같은 라벨끼리 묶을 수 있도록 구별할 수 있다 Classification 즉, 지도 학습이다.
인기글
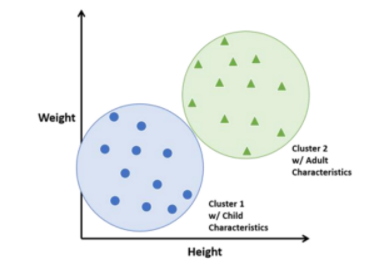
위 그림과 같이 데이터에 별도로 레이블이 지정되지 않고 데이터 유사도에 따라 최적의 그룹을 찾아서 묶어서 구분할 수 있습니다.
클러스터링 즉, 비지도 학습이다.
클러스터링는 일반적으로 고객을 세분화하거나 유사 문서를 군집화하는 등에 주로 사용된다.
이번 Clustering을 실습하기 위해 사용하는 데이터도 고객에 대한 정보가 포함된 데이터다.
데이터는 Kaggle의 Mal Customer Segmentation Data를 사용했다.
(https://www.kaggle.com/datasets/vjchoudhary7/customer-segmentation-tutorial-in-python)
데이터를 다운로드한 후 어떻게 구성되어 있는지 파악해야 합니다.
쇼핑몰 고객 데이터의 경우 총 4개의 열로 구성되며 내용은 다음과 같습니다.
- 성별: 성별 (Male, Female)
- Age: 나이
- Annual Income (k$) : 연간 소득
- Spending Score (1-100): 쇼핑몰에서 부여한 고객 점수
먼저 다운로드한 데이터를 출력해 봅시다.
df = pd.read_csv("Mall_Customers.csv", index_col = 0)
df.head()
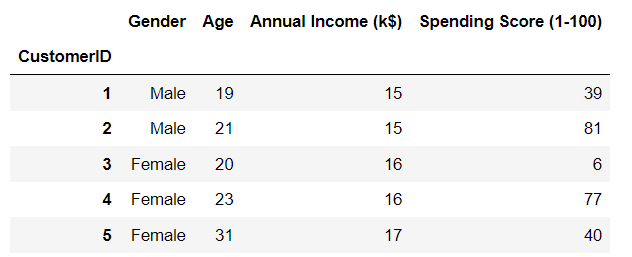
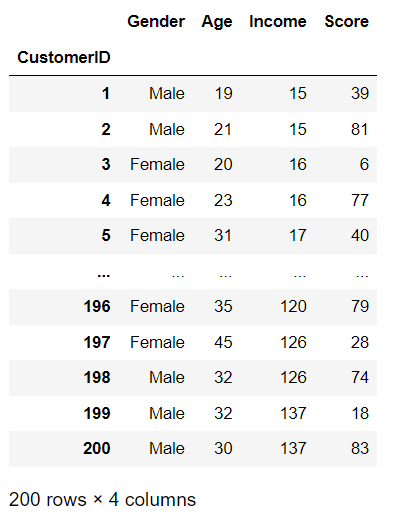
먼저 column의 이름을 나중에 사용하기 쉽도록 번영했습니다.
df = df.rename(columns = {'Annual Income (k$)':'Income', 'Spending Score (1-100)':'Score'})
df
지금 데이터를 읽었으므로 EDA를 시작합시다.
먼저 데이터의 데이터 유형, 숫자 등에 대한 정보를 살펴 보겠습니다.
df.info()

Gender 열을 제외한 나머지 열의 데이터 형식이 int 형식인지 확인할 수 있습니다.
또한, 결측치는 별도로 존재하지 않는 것을 알 수 있다.
df.describe()
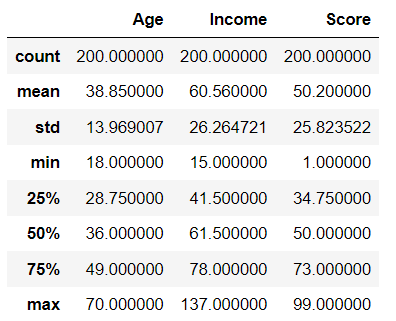
각 변수의 평균값과 표준 편차에는 차이가 있습니다.
물론, 단위가 다르게 발생하는 당연한 결과이며, 학습을 위해서는 정규화와 표준화 작업이 필요하다고 생각된다.
이제 데이터 분포가 어떻게 수행되는지 살펴보겠습니다.
현재 데이터의 변수는 Categorical 변수 1개그리고 Numerical 변수 3개로 구성되어 있습니다.
우선, Categorical 변수인 Gender 변수의 분포를 확인하였다.
print("column : Gender")
print(df('Gender').value_counts())
print('='*80)
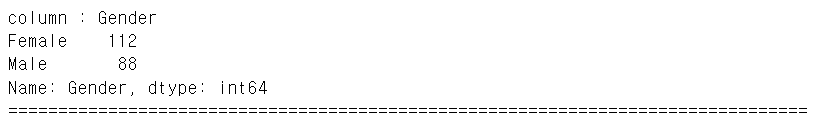
위의 숫자를 막대 그래프로 시각화하면 다음과 같습니다.
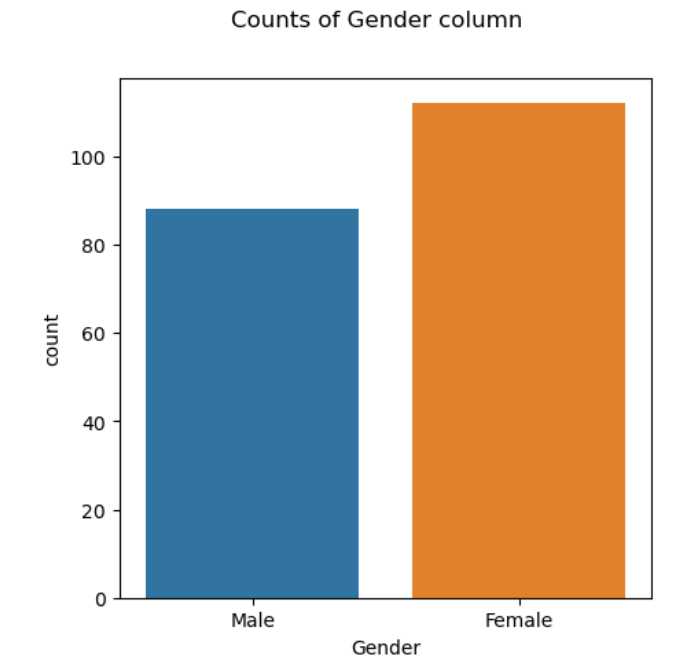
남성 고객에 비해 여성 고객의 수가 많은 것을 확인할 수 있다.
다음으로 Numerical 변수인 Age, Income, Score에 대해 시각화해 봅시다.

- Blue: Male
- Red:Female
여성과 남성의 나이, 소득, 점수 분포는 비슷합니다.
그런 다음 연속 변수 Age, Income 및 Score 변수의 상관 관계를 조사해야 합니다.
df_corr = df.corr()
display(df_corr)
위의 수치로 히트맵으로 시각화를 해보자.
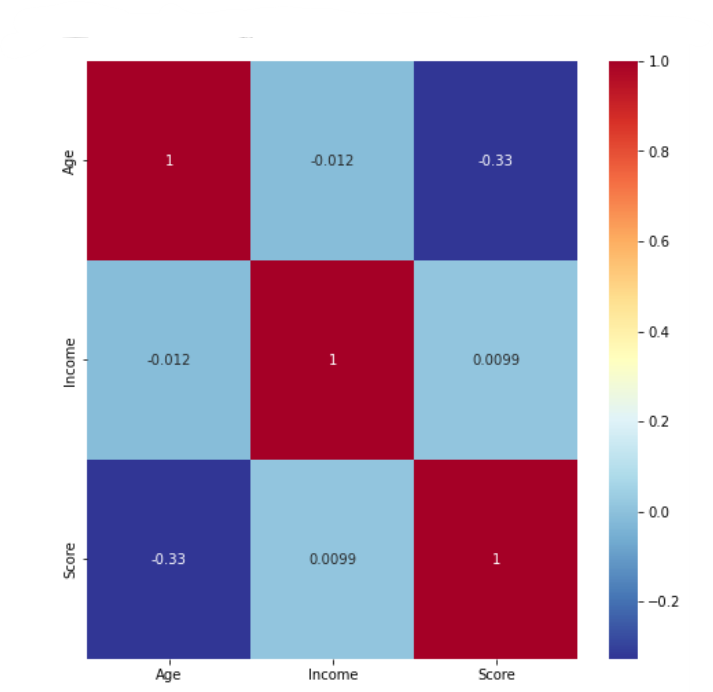
다른 열과 비교하여 나이 그리고 점수 컬럼의 상관 관계가 높아졌다.