
5주차 교육에 관한 회고(4L)
이번 주에도 열심히 유데미 강의를 들었다.
타블로, 파이썬 시계열 분석 강의의 총 2 개였다.
타블로에서 강의를 듣는데 세심한 주의를 기울여 공부하고 있는지 생각보다 오래 걸려 마음이 빨라졌다…
그리고 금요일에 중간 평가를 했다.
파이썬과 SQL의 총 20가지 문제였지만 SQL이 생각했던 것보다 더 어려웠습니다.
생각보다 시간이 많이 꽉 이번주는 매우 잘생겼다.
다음주부터는 오프라인 강의가 진행되기 때문에, 이전의 디자인의 싱킹 강의와 같이 조금은 즐겁게 할 수 없는 것일까? 라는 기대를 해 본다…
인기글
1. 이번 주 수업에서 좋았던 점은? (Liked)
2. 이번 주 새로 배운 것은? (Learned)
3. 배운 것에 대해 제가 부족한 부분은? (Lacked)
4. 앞으로 무엇을 해야 할까? (Longed for)
1. 이번 주 수업에서 좋았던 점은? (Liked)
✔ 신중하게 공부한 자신
유대미 강의를 빨리 들을 수도 있었지만, 그보다는 이해하면서 듣는 것이 좋다는 판단을 하고 꼼꼼히 들었다.
지금은 강의가 밀리는 편이 좋지 않지만, 나중에 타블로, 시계열 자료를 다룰 때는 더 도움이 되지 않을까 하는 생각을 했다.
또한 그만큼 꼼꼼하게 TIL을 만들었으므로 혼란이있을 때 TIL도 큰 도움이 될 것 같다!
2. 이번 주 새로 배운 것은? (Learned)
✔Python 기본 문법 복습 및 시계열 자료
파이썬에서 Numpy를 제대로 공부한 적이 없어서 잘 몰랐지만 이번에는 유데미 강의를 통해 제대로 공부할 수 있었다.
시계열과 관련된 statsmodels 라이브러리는 처음 보았지만 … 통계 지식이 가득하고 정말 어려웠습니다.
3. 배운 것에 대해 제가 부족한 부분은? (Lacked)
✔ SQL
SQL을 주로 사용해 프로젝트를 진행했지만, 이번 중간 평가에서 SQL 문제를 많이 잘못했다.
데이터베이스에 대한 지식이 부족하여 특정 SQL 문법을 명확하게 모르고 쿼리를 정확하게 만들 수 없습니다.
이번 중간평가를 통해 부족한 부분을 깨닫게 됐다.
그래도 다행인 것은 4월부터 SQL 오프라인 강의+프로젝트를 진행한다는 점이다.
이를 통해 SQL의 역량을 다시 굳혀 성장시키고 싶다!
4. 앞으로 무엇을 해야 할까? (Longed for)
✔ 통계 강의
이번 파이썬 시계열 강의를 들으면서 통계 부분이 많이 어려웠고 이를 보완해야 한다는 생각이 들었다.
우선, 현재 개별 스터디를 진행하면서 수강하고 있는 통계 강의를 거의 모두 들어가지만, 다시 듣고, 제대로 정리해 나의 것으로 할 예정이다.
✔ 타블로 오프라인 강의
다음 주 월요일부터 타블로에서 오프라인 강의가 시작된다.
직접 강사님이 와서 오프라인에서 강의를 해주셔서 별도로도 타블로를 활용한 팀 활동과 과제를 수행해야 한다.
오프라인 강의이며, 팀원과의 활동도 함께 강사님께, 그리고 팀원들에게 많이 배울 수 없는가 하는 기대가 된다.
그만큼 나도 열심히 팀 멤버들에게 도움이 되도록 노력해 볼 예정이다!
😎
5주차 교육내용 – 23.03.06~23.03.10
📌 타블로에서 고급 강의
1) 계산된 필드 대 테이블 계산
– 계산된 필드: 집계 전에 실행되고 데이터 세트 레벨에서 실행됩니다.
계산된 필드는 데이터세트를 분석하는 열로 포함할 새 측정값 또는 새 차원으로 만들고자 할 때 사용됩니다.
– 테이블 계산: 집계 후 실행되며 타블로 자체에서 계산됩니다.
✅ 함수를 활용해 독자적인 테이블 계산을 작성해, 이것을 그래프에 적용해 볼 수 있다.
– 이동 평균 함수(현재 행보다 왼쪽, 오른쪽에 있는 n개의 막대의 평균) : Window_avg
WINDOW_AVG(sum((Tones)), -7, 0)window는 작업하려는 행의 일부와 간격을 의미합니다.
현재 막대에서 n개의 막대의 이동 평균을 나타냅니다(빨간색 상자 처리).
아래 그래프는 총 8개의 막대의 평균을 보여줍니다.

이와 같이 기간을 설정하여 이동 평균을 계산하면, 7일간의 데이터가 없는 경우에는 계산적 오차가 발생한다.
따라서 이를 방지하기 위해 조건을 추가할 수 있다.
✅ 데이터가 부족한 경우 이동 평균을 계산하지 않는 조건 추가
# 막대(데이터)의 갯수가 8이면 막대의 평균을 반환하고 그렇지 않으면 0을 반환한다.
IF (WINDOW_COUNT((Idle Capacity Percent Pos), -7, 0) = 8)
THEN WINDOW_AVG((Idle Capacity Percent Pos), -7, 0)
ELSE NULL
END
그래프가 변경되었는지 확인할 수 있습니다.


2) 데이터 예측
타블로에서도 시계열 데이터는 이후의 데이터를 예측할 수 있다.
→ 분석 > 모델 – 예측 드래그

예측 옵션을 변경할 수 있습니다.
→ 오른쪽 클릭 > 예측 > 예측 옵션

옵션을 변경하면, 3년치의 데이터가 예측되어 나타난다.

3) 애니메이션
시간이 지남에 따라 데이터가 어떻게 변하는지를 보여주는 기능입니다.
다양한 기능이 있으며 흔적을 남길 수 있으며 다른 데이터를 비교할 수도 있습니다.
✅ 원하는 데이터 비교
→ 수동으로 마크 설정 > 데이터 선택 > 오른쪽 클릭 > 페이지 기록 – 항상 표시

✅ 특정 지역 전체의 데이터 확인
→ 표시를 하이라이트로 설정 > 지역에서 원하는 지역을 클릭

4) 상세 계산 레벨
– 상세 계산 레벨 방법: ①포함/②제외/③고정
①포함
INCLUDE 매개변수 작성 → {INCLUDE 포함하고 싶은 것 : 원하는 계산}
# LOD INCLUDE City Profit
{INCLUDE (City) : SUM((Profit))}
②제외하다
EXCLUDE 매개변수 작성 → {EXCLUDE 포함하고 싶은 것 : 원하는 계산}
# LOD EXCLUDE City Profit
{EXCLUDE (City) : SUM((Profit))}
③고정하다
FIXED 파라미터 작성 → {FIXED 포함하려는 항목: 원하는 계산}
# LOD FIXED City Profit
{FIXED (Country), (State), (City) : SUM((Profit))}
5) 고정 매핑 기술
주어진 x, y 위치를 이용하여 다각형을 그릴 수 있습니다.
→마크 > 폴리곤
→ 경로 > Path Order 추가

이것을 활용하여 도면에 다각형을 그려, 도면 내의 각 위치의 현상을 한눈에 파악할 수 있다.
① 열과 행에 X, Y 설정
② 자세히로 Room 드래그 > 마크 – 다각형으로 설정 > 패스로 Path 드래그
③ 색으로 Room 드래그하여 회의실별 색을 다르게 설정
④ 필터로 Floor 설정하여 1층, 2층별 배경지도 작성
⑤ 배경지도에 이미지 삽입
→지도 > 배경 이미지 > 데이터 이름
⑥ 회의실별 예약 상황의 가시화
→ 예약 상황 필드를 컬러로 드래그

📌Python 기본 문법
1) Numpy
✅ 브로드캐스트 (Broadcasting)
파이썬 목록과 달리 함수와의 조작을 브로드캐스트 할 수 있다.
슬라이스를 기반으로 변수 재할당에 브로드캐스트를 수행하면, 기존 배열에 적용
arr = np.arange(0,11)
arr
(out) array(( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
slice_of_arr = arr(0:6)
slice_of_arr(:)=99
slice_of_arr
(out) array((99, 99, 99, 99, 99, 99))
# 기존 배열에 영향 받음
arr
(out) array((99, 99, 99, 99, 99, 99, 6, 7, 8, 9, 10))
따라서 기존 배열의 영향을 받지 않도록 하려면 사본을 만들어야 합니다.
arr_copy = arr.copy()
arr_copy(:) = 1000
arr_copy
(out) array((1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000))
# 기존 배열에 영향을 받지 않는다.
arr
(out) array((99, 99, 99, 99, 99, 99, 6, 7, 8, 9, 10))
✅ 산술 계산
array끼리를 곱셈, 가산 등 다양한 산술 계산을 할 수 있다.
Numpy는 0 또는 무한으로 분할하는 작업을 수행할 때 오류를 발생시키는 대신 경고를 표시하고 값을 출력합니다.
arr = np.arange(0,10)
arr
(out) array((0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
# 1. 0을 0으로 나누었을 때, nan 값이 출력이 됨 (+ 경고 메시지 출력)
arr/arr
(out)
<ipython-input-5-4a148932dd5e>:5: RuntimeWarning: invalid value encountered in true_divide
arr/arr
array((nan, 1., 1., 1., 1., 1., 1., 1., 1., 1.))
# 2. # 0이 아닌 값을 0으로 나누면 inf로 출력이 됨 (+ 경고 메시지 출력)
1/arr
(out)
<ipython-input-6-2ee210defa4b>:3: RuntimeWarning: divide by zero encountered in true_divide
1/arr
array(( inf, 1. , 0.5 , 0.33333333, 0.25 ,
0.2 , 0.16666667, 0.14285714, 0.125 , 0.11111111))
2) Datetime Index
✅ Numpy Datetime Array
– numpy 데이터 유형 : datetime64
– Python에 내장 된 datetime 객체와 구별됩니다.
– 3개의 날짜 형식 문자열을 입력한 후 dtype=”datetime64″를 추가하면 datetime 형식으로 지정됩니다.
– ‘datetime64(D)’ :D는 일(일)을 나타낸다.
→ 이것으로 기본적으로 numpy 레벨 날짜 정밀도 적용한 것을 알 수 있다.
– 만약 다른 수준의 날짜 정밀도를 적용하려면 (h), (Y)을 함께 입력하면 된다.
np.array(('2016-03-15', '2017-05-24', '2018-08-09'), dtype="datetime64")
# (out) array(('2016-03-15', '2017-05-24', '2018-08-09'), dtype="datetime64(D)")
✅ Pandas Datetime Index
Pandas는 datetime 객체에 유연합니다.
datetime 객체에 대한 내장 유틸리티가 많이 있습니다.
💡 DatetimeIndex
– Pandas에는 datetime 색인이 있습니다.
– 시계열 데이터를 생성하려면 인덱스가 DatetimeIndex 데이터 형식이어야 합니다.
– 특정 순간에 기록된 타임스탬프 형식의 시계열 데이터를 처리하기 위한 인덱스
→ 메모 게시
Pandas는 문자열 코드를 추론하는 데 탁월합니다.
→ 다양한 날짜와 시간 형식을 사용할 수 있습니다
그러나 Pandas는 날짜를 미국 스타일의 날짜 형식으로 추측합니다.
pd.to_datetime(('2/1/2018','3/1/2018'))
(out) DatetimeIndex(('2018-02-01', '2018-03-01'), dtype="datetime64(ns)", freq=None)
유럽 스타일의 날짜 형식으로 변환하려면 직접 형식을 지정합니다.
→ format =
pd.to_datetime(('2/1/2018','3/1/2018'), format="%d/%m/%Y")
(out) DatetimeIndex(('2018-01-02', '2018-01-03'), dtype="datetime64(ns)", freq=None)
📌 Statsmodels를 이용한 시계열 데이터 분석
1) statsmodels 라이브러리
시계열 예측에 사용되는 주 라이브러리
다양한 통계 모델의 추정과 통계 검정, 통계적 데이터 탐색 등을 다루는 클래스와 함수를 제공하는 Python 모듈이다.
✅ 시계열 데이터
– 추세 : 시계열 데이터는 경향이 있을 수 있다.
– 계절성 : 반복 트렌드(주지의 주기이며 매년 반복됨)
– 순환 요소 : 반복성이 없는 요소
✅ 호드릭 – 프레스코트 필터
✔ tsa : 시계열 분석 모듈
✔ hp_filter : 호드릭 – 프레스코트 필터
from statsmodels.tsa.filters.hp_filter import hpfilter
순환 요소, 추세 요소 두 데이터를 반환따라서 반환 값인 튜플을 압축 해제합니다.
gdp_cycle, gdp_trend = hpfilter(df('realgdp'), lamb=1600)
추세 요소를 추세 열로 추가하여 추세 요소와 실제 추세 값을 시각화합니다.
df(('trend','realgdp')).plot(figsize=(12,8)).autoscale(axis="x",tight=True);

2) ETS 모델(Error/Trend/Seasonality Models)
✅ETS 모델
오차(E), 트렌드(T), 계절성(S)의 약어로 지수 평활법과 ETS 분해, 트렌드 모델 등 다양한 모델을 포함한 일반적인 표현입니다.
오차(E), 추세(T), 계절성(S) 세 가지 요소를 더하거나, 곱하거나, 일부를 사용하지 않고 데이터를 평활화합니다.
모델에 따라 주요 요소를 기반으로 데이터에 맞는 일반화 모델을 만들 수 있습니다.
✅ETS 모델의 종류
추가 모델 : 경향이 선형에 가까운 계절성이 거의 일정하게 보이는 경우에 적용
곱셈 모델 : 지수적 증감의 경우 등 비선형적으로 증가 또는 감소하는 경우에 적용
statsmodels의 ETS 분해 수행그러면 datetime을 x축으로 그린 네 개의 플롯을 반환합니다.
– 처음: 풀 그래프
– 두 번째: 트렌드 그래프 → 데이터의 전반적인 상승 추세 또는 하향 추세를 표시합니다(추세가 지수형인지 선형인지 확인할 수 있음)
– 세 번째: 계절성 그래프 → 트렌드 요소를 제거한 계절성 요소
– 네 번째: 잔차(오차) 항 그래프 → 트렌드, 계절성으로 설명되지 않은 잔차, 오차가 잔차항에 표시(노이즈)
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(airline('Thousands of Passengers'), model="multiplicative")
result.plot();
3) EWMA (지수 가중 이동 평균)
✅ SMA (단순 이동 평균)
# 6개월 이동 평균 컬럼
airline('6-month-SMA') = airline('Thousands of Passengers').rolling(window=6).mean()
# 12개월 이동 평균 컬럼
airline('12-month-SMA') = airline('Thousands of Passengers').rolling(window=12).mean()
airline.plot(figsize = (10, 8));

✅ EWMA (지수 가중 이동 평균)
최신 값에 적용되는 가중치는 매개변수에 의해 결정되며 이동 평균 기간에 따라 달라집니다.
ewm 메서드: 지수 가중 함수 제공
✔ span : 기간 설정 / 12개월(1년)
airline('EWMA12') = airline('Thousands of Passengers').ewm(span=12,adjust=False).mean()
시작과 끝은 조금 다르게 보입니다.
계절성 경향이 끝날수록 더 잘 보입니다.
→ 오래된 자료보다 최신 자료에 큰 가중치를 두었기 때문에
SMA와 EWMA를 비교하면 EWMA가 좀 더 실제 추세선과 비슷하다는 것을 알 수 있습니다.
airline(('Thousands of Passengers','EWMA12','12-month-SMA')).plot(figsize=(12,8)).autoscale(axis="x",tight=True);

4) Holt-Winters Methods (홀트 윈터스 계절성 기법)
– 예측식 외에 3개의 평활식으로 구성
→ 레벨: l_t, 추세 요소: b_t, 계절성 요소: s_t
→ 각각에 대응하는 평활 파라미터: α, β, γ
– 계절적 요소를 다루는 방법
→ 가산 방법: 계절성 요소가 데이터 전체에 일정한 폭으로 표시되는 경우에 사용
→승산 기법: 계절 변동폭이 데이터 레벨에 비례하여 나타나는 경우에 사용
✅ 지수 가중 이동 평균
– ewm() 메서드 vs SimpleExpSmoothing 메서드
→ ewm() 메소드를 이용한 지수 가중 이동 평균과 SimpleExpSmoothing 메소드를 이용해 데이터에 적합하는 모델을 피팅한 값이 동일한 것을 확인하고 싶다.
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
# span, alpha 값 설정
span = 12
alpha = 2/(span+1)
# ewm() 메소드
df('EWMA12') = df('Thousands of Passengers').ewm(alpha=alpha,adjust=False).mean()
# SimpleExpSmoothing 메소드
df('SES12')=SimpleExpSmoothing(df('Thousands of Passengers')).fit(smoothing_level=alpha,optimized=False).fittedvalues.shift(-1)
df.head()
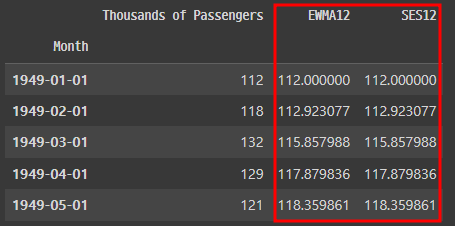
▶ SimpleExpSmoothing 결과가 지수 가중 이동 평균값과 동일한지 확인할 수 있다.
✅ 이중 지수 평활법 (홀트 기법)
from statsmodels.tsa.holtwinters import ExponentialSmoothing
# 덧셈 모형 사용
df('DESadd12') = ExponentialSmoothing(df('Thousands of Passengers'), trend='add').fit().fittedvalues.shift(-1)
# 곱셈 모형 사용
df('DESmul12') = ExponentialSmoothing(df('Thousands of Passengers'), trend='mul').fit().fittedvalues.shift(-1)
df.head()

▶ 곱셈 모델이 실제 데이터에 가까운 예측을 하고 있다 → 곱셈 모델을 사용해야 합니다.
✅ 삼중지수 평활법(홀트 윈터스 계절성 기술)
계절성을 표현하는 새로운 평활 파라미터인 감마가 추가됩니다.
계절성 요소를 나타내는 c_t라는 새로운 요소가 추가되어 감마로 표시됩니다.
예측 모델에서 L은 사이클당 데이터 포인트 수입니다.
# 추세 : 덧셈 모형 → trend='add'
# 계절성 : 덧셈 모형 → seasonal="add"
df('TESadd12') = ExponentialSmoothing(df('Thousands of Passengers'),trend='add',seasonal="add",seasonal_periods=12).fit().fittedvalues
# 추세 : 곱셈 모형 → trend='mul'
# 계절성 : 곱셈 모형 → seasonal="mul"
df('TESmul12') = ExponentialSmoothing(df('Thousands of Passengers'),trend='mul',seasonal="mul",seasonal_periods=12).fit().fittedvalues
df.head()

이중 대 삼중 지수 평활법을 비교해 보았다.
df(('Thousands of Passengers','DESmul12','TESmul12')).iloc(:24).plot(figsize=(12,6));

▶ 삼중지수 평활법에 의한 예측은 실제 데이터에 가깝다.
📌 중간 평가 (SQL)
중간 평가 SQL 문제 사이에 기억하는 잘못된 문제의 개념을 다시 시작하려고합니다.
1) LIMIT
- LIMIT는 출력할 수를 제한합니다.
- 포맷: LIMIT start, number = LIMIT number OFFSET start
- LIMIT는 첫 번째 데이터를 0으로 설정하여 시작합니다.
평균 키(height)가 4~5번째로 큰 회원을 추출한다(출처:혼공 SQL)
select mem_name, height from member
order by height desc
limit 3, 2; -- 3번째부터 2건 조회

2) 테이블 복사
필드 유형과 숫자가 같은 두 테이블의 데이터 복사
✅ 복사한 데이터를 포함하는 테이블이 없는 경우 → 테이블 만들기 + 테이블 복사
CREATE TABLE (생성 테이블) SELECT * FROM (원본 테이블)
# 기본 모드 데이터까지 복사
SELECT * INTO (생성 테이블) FROM (원본 테이블명)
# 데이터 없이 테이블의 구조만 복사
SELECT * INTO (생성 테이블) FROM (원본 테이블명) WHERE '1' = '2'
# 데이터까지 복사하기
SELECT * INTO (생성 테이블) FROM (원본 테이블명) WHERE '1' = '1'
✅ 복사한 데이터를 포함하는 테이블이 존재하는 경우 → 테이블 복사
INSERT INTO (생성 테이블) SELECT * FROM (원본 테이블)
✅ 다른 DB 간의 테이블 복사
INSERT INTO (복사 데이터베이스).(복사 테이블)
SELECT * FROM (원본 데이터베이스).(원본 테이블)
🔎 노트 게시물
(MS SQL) 테이블 복사(다른 DB 간 복사 포함)
필드의 유형과 필드의 숫자가 같은 두 테이블 사이의 데이터를 복사하는 방법입니다.
복사한 데이터를 넣는 테이블이 존재하지 않는 경우(테이블 작성+테이블 복사) □ Create Table(대상 테이블
overit.
시각화 업로드한 Tableau Public
송아지 – Profile | Tableau Public
모란의 Tableau Public profile. View interactive data visualizations published by this author.
public.tableau.com
이번 주에 만든 TIL
(스타터스 TIL) 20일째. Tableau에 고집 (1) – 그룹, 집합, 테이블 계산, 데이터 소스 필터
(스타터스 TIL) 21일째. Tableau에 충실(2) – 애니메이션, 상세 레벨 계산(LOD), 고급 매핑 기술
(스타터즈 TIL) 22일째.
(스타터스 TIL) 23일차. 시계열 데이터 분석 with Python (2)
(스타터스 TIL) 24일째. 시계열 데이터 분석 with Python (3)
* 유데미큘레이션 단축키: https://bit.ly/3HRWeVL
* STARTERS 취업 부트 캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
이 리뷰는 유데미-은진싱크 빅 취업 부트캠프 4기 데이터 분석/시각화 학습 저널 리뷰로 작성되었습니다.