관련성 분석 개요
- 여러 거래, 사건에 포함된 항목의 관련성을 파악하는 탐색적 데이터 분석
- 유사한 개를 그룹화하고 각 집단의 특성을 파악하기 위해 활용
- 사건 관련 규칙을 찾는 기법에서 목표 변수가없는 비지도 학습
- 콘텐츠 기반 추천의 기본 방법론
- 그룹의 특성화는 군중 분석과 병행 가능하며 장바구니 분석이라고도합니다.
관련 규칙 (Assocication Rule) 순서
- 데이터 간 규칙 만들기
- if 조건절(Antecedent) > 결과절(Consequent)
- 어떤 규칙이 데이터 속성에 맞는지 기준으로 설정
- 지도(supprt)
- 데이터 전체에서 해당 상품을 고객이 구매한 확률
- 신뢰도
- 한 데이터를 구매할 때 다른 제품을 구매할 조건 확률
- P(A,B) / P(A)
- 향상도
- 두 상품을 구매할지 여부가 독립적인지 판단하는 개념
- P(A,B) / P(A)P(B)
- 1이라면 상호 독립 관계
- 1보다 큰 경우 양의 상관 관계
- 1보다 작으면 음의 상관관계
- 지도(supprt)
- 규칙의 유효성 평가(실제 규칙 만들기)
- 관련성 분석의 예
- 7가지 아이템을 구입할 수 있다고 가정
| ID | 우유 | 빵 | 버터 | 맥주 | 기저귀 | 계란 | 과일 |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| 3 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 4 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
| 5 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
- 지지도 확인, 지지도 = A와 B의 교합
- 신뢰도 확인, 신뢰도=교집합*조건부 확률(A를 사서 B를 사는 확률)
| 조건 – 결과 | 지지 맵(support) (교합) |
지도 * 신뢰도(confidence) (교차 집합 * 조건부 확률) |
| 우유를 사면 빵을 사 | 2/5 = 0.4 | 0.4*1.0 = 0.4 |
| 우유를 사면 계란을 사 | 1/5 = 0.2 | 0.2*0.5 = 0.1 |
| 빵을 사면 과일을 사 | 2/5 = 0.4 | 0.4*0.66 = 0.264 |
| 과일을 사면 계란을 사 | 2/5 = 0.4 | 0.4*0.66 = 0.264 |
| 우유와 빵을 사면 과일을 사 | 2/5 = 0.4 | 0.4*1.0 = 0.4 |
- 향상도 확인, 향상도=A와 B의 화집합/A*B
- 빵과 우유의 향상도 1 이상이므로 양의 상관 관계
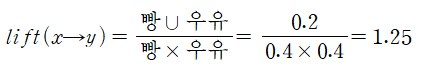
앱리오 알고리즘
- 최소 지도 이상의 빈발 항목 집합만을 찾아 관련 규칙을 계산하는 기법
- 최소 지지도 이상의 1항목 집합이 빈발이면
- 이 항목 집합의 모든 하위 집합은 자주 항목 집합이며 관련 규칙 계산에 포함됩니다.
- 이 항목 집합의 모든 하위 집합은 자주 항목 집합이며 관련 규칙 계산에 포함됩니다.
- 최소 지지도 미만의 항목 집합이 비빈발인 경우
- 이 항목의 집합을 포함한 모든 집합은 비빈발 항목 집합으로 전정 진행
- 그런 다음 최소 신뢰도 기준을 적용하여 최소 신뢰도에 도달하지 않은 관련 규칙을 다시 제거하여 반복 작업을 수행합니다.
- 새로운 관련 규칙이 없을 때까지 진행
관련성 분석의 장점과 단점
- 장점
- 분석 결과를 이해하기 쉽고 실제 적용에 용이
- 단점
- 항목이 많을수록 관련 규칙이 더 많이 발견되지만 의미에 대해 미리 결정해야 합니다.
- 상당수의 계산 과정이 필요
- 항목이 많을수록 관련 규칙이 더 많이 발견되지만 의미에 대해 미리 결정해야 합니다.