최근에는 Multi-GPU 학습을 쓰는 경향이다!
-> 오늘의 딥 러닝은 방대한 데이터와의 싸움
Muti-GPU 개념
- Single vs. 멀티: 싱글은 1개, 멀티는 2개
- GPU vs. Node : Node = 시스템(한 대의 컴퓨터), GPU = 하나의 노드에 있는 GPU를 의미합니다.
- Single Node Single GPU: 한 대의 컴퓨터에 하나의 GPU
- 단일 노드 멀티 GPU: 한 대의 컴퓨터에 여러 GPU
- 다중 노드 다중 GPU: 여러 컴퓨터에서 여러 GPU
Model parallel
- 여러 GPU에 학습을 분산시키는 두 가지 방법 -> 모델 분할/데이터 분할
- 모델을 분리하는 것은 생각보다 오래전부터 썼다 (alexnet)
- 모델의 병목 현상, 파이프라인의 어려움 등에 의한 모델 병렬화는 고난이도 과제
– Alexnet (Multi – GPU) -> Model parallel

Alexnet 문제
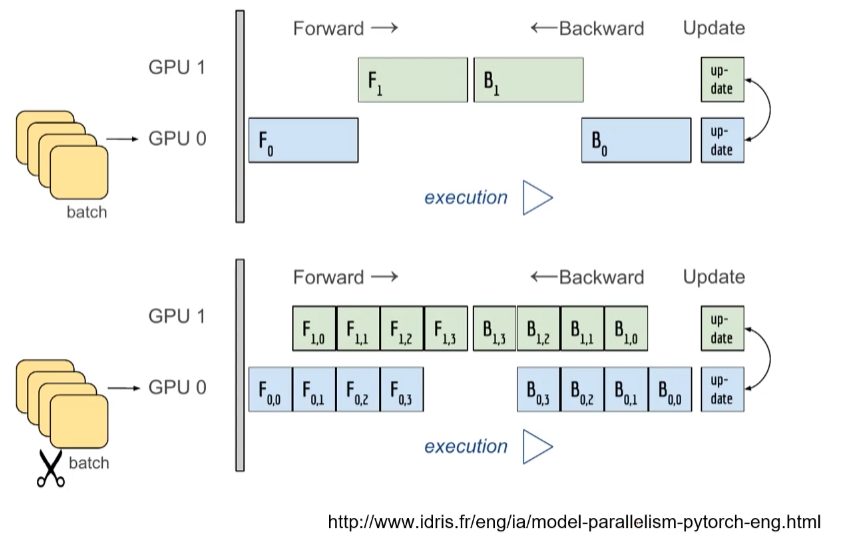
각각의 시간에 맞추어 돌아가지 않으면 병렬화의 의미가 있지만, 위에는 병렬화의 의미가 없다.
– 데이터 parallel
- 데이터를 분할하고 GPU에 할당한 후 결과의 평균을 얻는 방법
- minibatch 식과 비슷하지만 한 번에 여러 GPU에서 실행

- PyTorch는 다음 두 가지 방법을 제공합니다.
- DataParallel, DistributedDataParallel
- Data Parallel – 단순히 데이터를 분해하고 평균을 취합니다.
- GPU 사용 불균형 문제 발생, Batch 크기 감소(1GPU 병목), GIL
- DistributedDataParallel
- 각 CPU에 process를 생성하여 개별 GPU에 할당
- 기본적으로 DataParallel에서 하나의 개별 작업 평균
- 각 CPU에 process를 생성하여 개별 GPU에 할당
- Data Parallel – 단순히 데이터를 분해하고 평균을 취합니다.
- DataParallel, DistributedDataParallel